문제 정의:
목표는 calibrated 된 카메라를 이용해 촬영된 인물의 head pose와 추정된 head pose의 uncertainty를 world coordinate frame에서 모델링 하는 것을 목표로 한다.
+ 추가로 head pose(=face pose)를 이용해 인물의 시선을 예측하고 예측된 gaze point의 불확실성을 구하는 것까지 해본다.
노테이션 정의:
Pose $X^{frame}_{object}=(\psi, \phi, \theta, x, y, z) \in R^6$는 기준 coordinate frame 상에서 object의 pose 를 나타낸다.
$$\psi : z axis 를 회전 축으로 하는 회전 각도, 단위:degree. $$
$$\phi : y axis 를 회전 축으로 하는 회전 각도, 단위: degree. $$
$$\theta : x axis 를 회전 축으로 하는 회전 각도, 단위: degree. $$
$$ x : object 의 x 좌표 $$
$$ y: object 의 y 좌표 $$
$$ z: object 의 z 좌표 $$
단, face coordinate frame 에서 face의 pose는 $X^{face}_{face}=(0,0,0,0,0,0)$ 으로 정의한다.
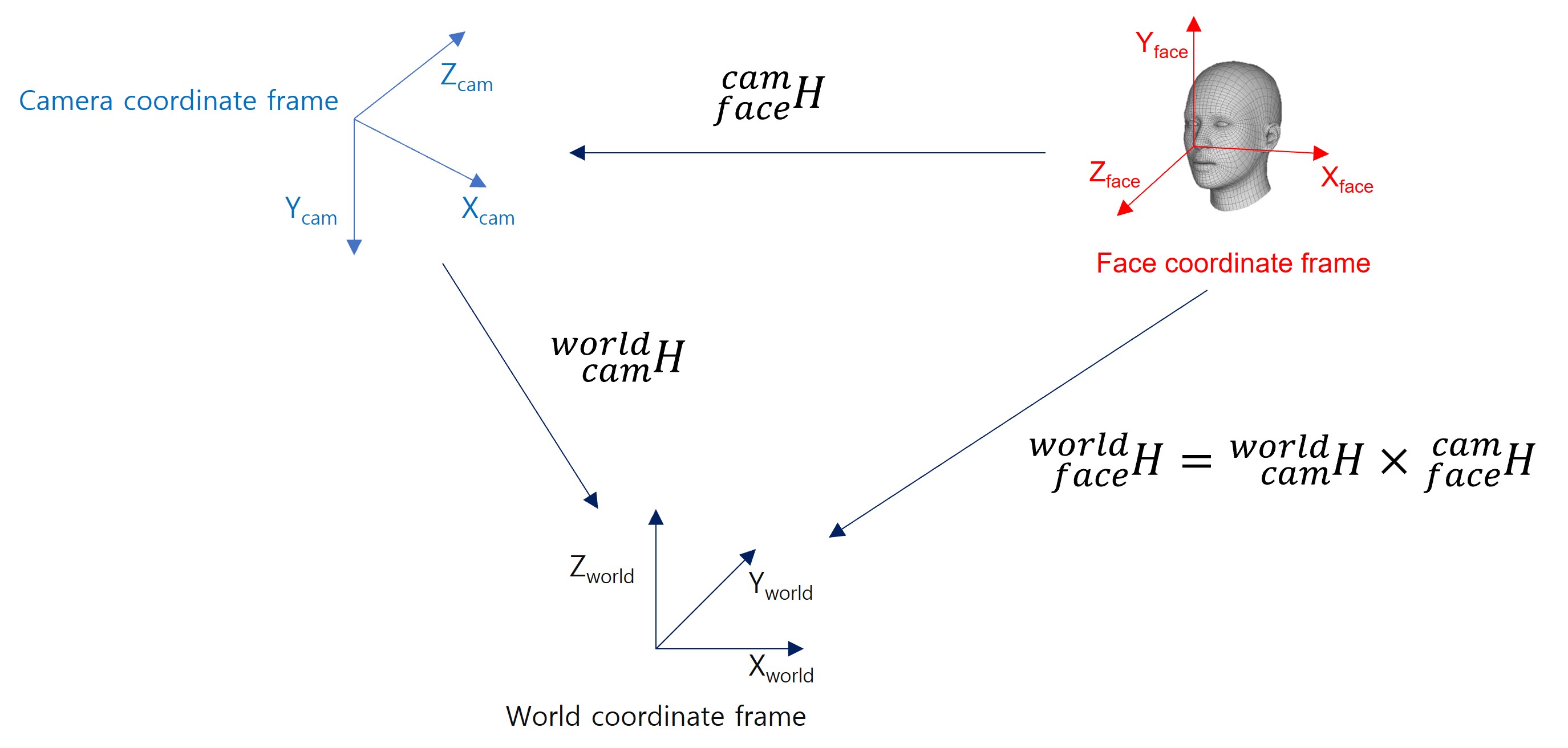
이 문제에서는 $X^{face}_{face}, X^{face}_{camera}, X^{camera}_{world} $ 3개의 pose 가 등장한다.
Pose 와 transformation matrix 관계
$$^{object}_{frame}H = f(X^{frame}_{object}) = \begin{bmatrix}^{object}_{frame}R&-^{object}_{frame}RT_{object}\\0&1\\ \end{bmatrix}$$
$$^{object}_{frame}R=Rz(\psi)Ry(\phi)Rx(\theta), T_{object}=\begin{bmatrix} x\\y\\z \end{bmatrix}$$
$$p^{object} = ^{object}_{frame}H \times p^{frame}, p^{frame}=\begin{bmatrix} x\\y\\z\\1 \end{bmatrix}$$
$$^{world}_{face}H = ^{world}_{camera}H \times ^{camera}_{face}H$$
$$X^{frame}_{object}=f^{-1}(^{object}_{frame}H)$$
좌표계 정의
Pose 추정
$X^{face}_{camera} = SolvePnP(q^{face}_{i}, p^{image}_{landmark-i},K, dist)$
$X^{camera}_{world} = SolvePnP(q^{world}_{i}, p^{image}_{target-i}, K, dist)$
K: projection matrix, dist = distortion parameter
$p^{image}_{landmark-i}$ : image 좌표계 상의 i번째 face landmark 점 좌표 (x,y).
$q^{face}_{i}$ : face coordinate frame 상의 $ p^{image}_{landmark-i}$ 대응점 (x,y,z).
$p^{image}_{target-i}$ : image 좌표계 상의 i번째 calibration target landmark 점 좌표 (x,y).
$q^{world}_{i}$ : world coordinate 상의 $p^{image}_{target-i}$ 대응점 (x,y,z).
추정 오차 공분산 계산:
$p^{image}_{i} = f(X^{face}_{camera}) \times q^{face}_{i}$ 이 수식을 테일러 시리즈를 이용해 선형 근사 하면
$ \overline{p}^{image}_{i}+\Delta p = f( \overline{X}^{face}_{camera}+\Delta X) \times q^{face}_{i} $
$\Delta p \approx \frac{\partial f}{\partial X} \Delta X^{face}_{camera} = M_{i} \Delta X^{face}_{camera}$
이 식을 least square 로 풀면 Pose $X^{face}_{camera}$ 의 추정 오차 공분산은
$C_{x} = E[\Delta X \Delta X^{T}] = (M^{T}M)^{-1}M^{T}E(\Delta p \Delta p^{T})((M^{T}M)^{-1}M^{T})^{-1}$
$E(\Delta p \Delta p^{T}) : ^{camera}_{face}H 를 이용해 projection 한 point의 공분산 행렬$ 로 나타낼 수 있다.
$C_{x}$는 6x6 사이즈의 행렬이다.
World-camera 의 추정 오차 공분산 행렬도 $C_{w} = 6 \times 6$ 이고 위와 동일 한 방식으로 calibration target을 이용해 구할수 있다.
최종 $^{world}_{face}H$의 추정 오차 공분산을 $C_{y}$ 라 하면
$X^{face}_{world}=f^{-1}(^{world}_{face}H)$
$^{world}_{face}H= ^{world}_{camera}H \times ^{camera}_{face}H = f(X^{camera}_{world}) \times f(X^{face}_{camera})$ 관계에 의해 공분산 전파(propagation) 식에 의해 아래와 같이 구할 수 있다.
$C_{y} = J_{X} C_{x} J^{T}_{X} + J_{W} C_{W} J^{T}_{w}, C_{y} = 6 \times 6 행렬$
$J_{x} = \frac{\partial f^{-1}(^{world}_{face}H)}{\partial X^{face}_{camera}} $
$J_{w} = \frac{\partial f^{-1}(^{world}_{face}H)}{\partial X^{camera}_{world}} $
이를 이용해 face pose 는 world에서 $X^{face}_{world}=f^{-1}(^{world}_{face}H)$ 를 평균으로 하고 $C_{y}$ 분산으로 하는 gaussian pdf 를 따른다고 볼 수 있다.
다음으로 head pose로 부터 gaze point를 예측 해보자.
여기서는 시선의 방향이 얼굴의 전면부 즉 코끝이 가리키는 방향과 같다고 가정한다.
gaze point $g$를 아래와 같이 정의하자.
$$g=\begin{bmatrix} x_{g}\\y_{g}\\z_{g} \end{bmatrix} = p_{face} + tV_{gaze} = g(^{world}_{face}H) --------(func gaze)$$
$V_{gaze} =\begin{bmatrix} g_{x}\\g_{y}\\g_{z} \end{bmatrix}: gaze direction vector, ^{world}_{face}R의 마지막 컬럼, 즉 ^{world}_{face}H[:,2] = f(X^{face}_{world})[:,2]$
$p_{face} = \begin{bmatrix} x_{face}\\y_{face}\\z_{face} \end{bmatrix}$, 얼굴 위의 한점 여기선 face coordinate frame origin의 world coordinate frame 상의 좌표로 설정, 즉 $^{world}_{face}H[:,3]=f(X^{face}_{world})[:,3]$
이때 $V_{gaze}$는 시선의 방향을 나타네는 벡터 즉 시선의 방향 벡터라고 볼 수 있다. 가정에 의해 시선의 방향은 얼굴 평면과 수직(perpendicular) 이므로 world 좌표계에서 head pose를 나타내는 rotation matrix의 3번째 컬럼 즉 face coordinate frame의 z axis에 해당한다. 3차원 공간상에서 방향벡터 $V$와 평행하고 사람의 얼굴 위의 한점(눈 사이의 한점을 잡는게 가장 좋으나 여기서는 코끝으로 가정했다.)을 지나는 직선을 구하는게 목적이므로 $p_{face}$는 코끝의 world coordinate frame 상의 좌표로 가정하자.
이렇게 하면 world coordinate frame 상의 z-x평면위에서 이미지 상의 특정 인물이 바라보고 있는 좌표(gaze point)와 불확실성은 아래와 같이 구할 수 있다.
$t= -\frac{p_{face}}{g_{y}} $ 로 설정 하면 y=0이 되므로 world 좌표계 상에서 x,z평면과 만나는 gaze point를 구할 수 있고
gaze point 와 pose $X^{face}_{world}$의 관계에 따라 gaze point 의 공분산은
$C_{g} = J_{g} C_{y} J^{T}_{g} , 3 \times 3 행렬$
$J_{g} = \frac {\partial g(^{world}_{face}H)}{\partial g}, 3 \times 6 행렬$
로 구할 수 있다.
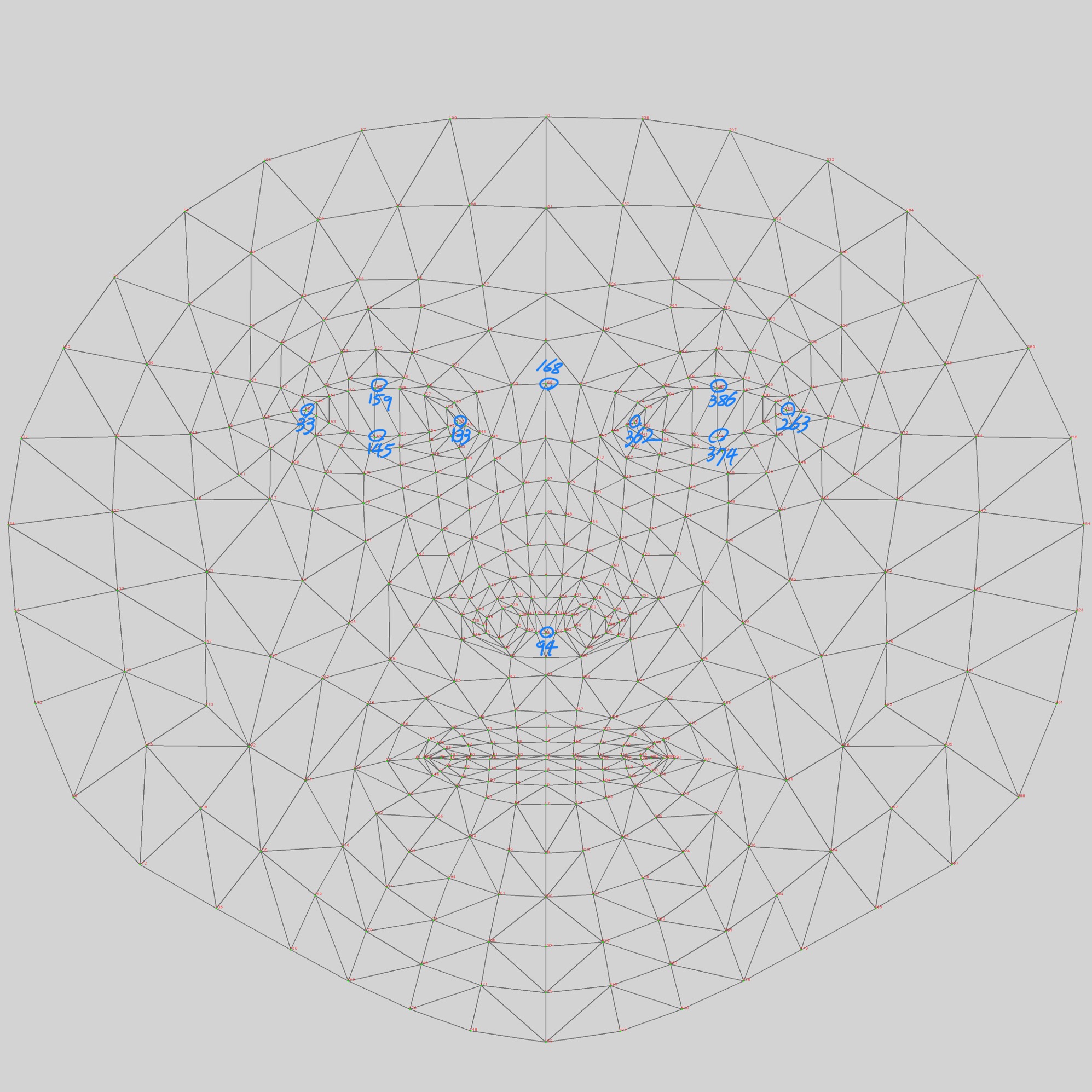
다음은 face pose(=head pose) estimation에 사용된 landmark를 표시한 그림이다.
'Deeplearning > toyproject' 카테고리의 다른 글
| [Deskew for ocr] Rotation correction v2 (0) | 2022.03.06 |
|---|---|
| [Deskew for ocr] Rotation correction (0) | 2022.02.15 |