
딥러닝 기반의 트래킹 로직을 간단히 정리하고자 한다.
정리할 대상은 다음 로직이다.
1.SORT
2.DeepSORT
이 포스팅에서 소개할 Multiple object tracking 패러다임은 tracking-by-detection으로 detection -> tracking 2단계로 이루어 진다. 당연하게도 detector의 성능이 좋아 지면 tracking도 더 잘될 확률이 높아진다.
트래킹도 내부적으로 motion estimation, data association, update 로 이루어져 있다.
motion estimation은 이전 프레임들에서 발견된 object bbox 들이 현재 프레임에서 어디에 위치 할 지 나이브하게 예측 하는 단계라고 보면 되고(베이지안적 시각으로 바라보면 prior distribution p(x) 에 해당), data associtaion은 연속된 프레임에서 bbox 가 서로 같은 object의 bbox 인지 best match를 찾는 과정이다(이 과정에서 best match를 찾는 것은 likelihood=p(z|x)에 해당한다. ). best match를 찾으면 motion estimation 의 output을 현재 프레임에서 찾은 bbox 정보를 이용해 update 한다.
트래킹 로직을 공부 할때 서로 다른 로직의 motion estimation 방식이 어떻게 다른지, data association을 위해 어떤 정보를 사용하는지 association에 사용하는 정보를 어떻게 구하는지 차이점을 위주로 파악 하면 이해하는데 도움이 된다.
SORT
sort 는 simple online realtime tracking 의 약자로 실시간 트래킹이 가능한 대표적인 접근 방식이다.
SORT 를 이해해 두면 아래 소개할 다른 로직들을 이해하는데 큰 도움이 되는 baseline 격이다.
SORT는 detector로 Faster Region CNN (FrRCNN) detection framework을 사용하고
motion estimation을 위해 kalman filter를 사용하고 data association을 위한 정보로 현 프레임에서 detector 가 구한 BBox와 tracking 된 object bbox 사이의 IOU 를 사용한다.

서로 다른 프레임 사이에서 object 들간의 best match 를 찾기 위해 IOU 값을 metric으로 hungarian algorithm을 이용해 best match 를 찾는다.
(kalman filter와 hungarian algorithm은 많은 트래킹 로직에서 사용되니 공부해 두면 다른 tracking 로직을 이해하는데 도움이 된다. hungarian algorithm은 많은 사람들이 잘 정리 해놔서 굳이 정리하지 않는다. )
kalman filter에서 각 object 의 state은 [ x,y, s, r, $\dot{x}$, $\dot{y}$, $\dot{s}$ ] 이다.
x, y는 object의 center position 이고 s는 scale r은 aspect ratio, $\dot{x}$, $\dot{y}$, $\dot{s}$ 는 x,y,s 의 속도 값이다.
SORT의 플로우를 diagram으로 그리면 아래와 같다.
단점: object에 occlusion 이 발생하는 경우, image frame 밖으로 나갔다가 다시 들어오는 경우(re-entering), object의 외향적 특징이 변하는 변한 경우(different view point) tracking이 잘 안된다. ID switching(동일 instance의 tracking id 값이 바뀌는 것) 바뀌는 문제의 발생빈도가 상대적으로 잦다.
DeepSORT
DeepSORT는 SORT의 단점을 보강하기 위해 data association에 사용하는 feature를 보강하고 추적한
object와 현재 프레임에서 detection한 object를 매칭 하는 방법을 강화한 버전으로 전체 플로우는 SORT와 유사하다.
주로 SORT의 단점으로 거론된 occlusion, re-entering 시 발생하는 id-switching 을 개선했다.
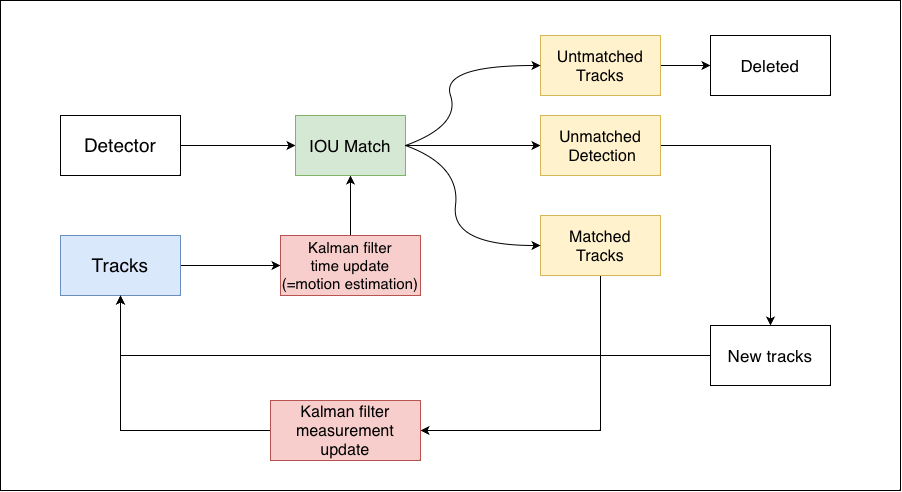
아래 flow diagram은 DeepSORT의 동작을 시각화 한것으로 동작방식을 잘 나타냈다. 붉은색으로 강조된 박스는 DeepSORT에서 추가된 기능에 해당 된다.
(모든 붉은색 블럭이 deepsort에만 있는건 아니다. iout 매칭의 결과로 나오는 unmatched track의 경우 기존 SORT에도 있지만 DeepSORT에서는 unmatched track에 대한 추가 처리를 하기 때문에 붉은색으로 표시했다.)

State of object in kalman filter
DeepSORT도 트래킹을 위해 기본적으로 kalman filter prediction(=motion estimation)과 update(=measurement update)를 이용한다.
이때 kalman filter에서 object state를 아래와 같이 정의 한다.
$( x,y,\gamma, h, \dot{x}, \dot{y}, \dot{\gamma}, \dot{h} )$
x,y: object center location, $\gamma$: aspect rati, $h$: object height 이고 $\dot{x}, \dot{y}, \dot{\gamma}, \dot{h}$ 는 각 변수의 속도에 해당한다.
Data association
SORT 에서 data association을 위한 정보(metric)으로 단순 iou 를 사용했던 것에 비해
DeepSORT는 총 세가지 메트릭(mahalanobis distance, appearance descriptor, iou)을 사용 하고 data association은 2단계로 이루어 진다. (Fig 3. 을 참조하면서 설명을 보자)
data association의 첫번째 단계는 cascade matching, 두번째 단계는 iou matching이다.
cascade matching은 mahalanobis distance와 appearance descriptor 두 가지 메트릭을 이용해 track과 detection사이의 matching관계를 구한다.
우선 mahalanobis distance와 appearance descriptor 에 대해 살펴 보고 이 두 가지를 이용해 cascade matching에서 어떻게 track-detection matching 쌍을 구하는지 알고리즘을 살펴 보자.
1. mahalanobis distance
mahalanobis distance는 distance를 구하기 위해 분산을 고려한다. 수식은 아래와 같다.
$$ d^{(1)}(i,j)=(d_{i} - y_{j})^{T} S^{-1} (d_{i} - y_{j})$$
$d_{i}$ 는 현재 프레임의 detection 결과, $y_{j}$는 kalman filter prediction의 결과, $\sum^{-1}$ 는 공문산 메트릭스의 역행렬이다.
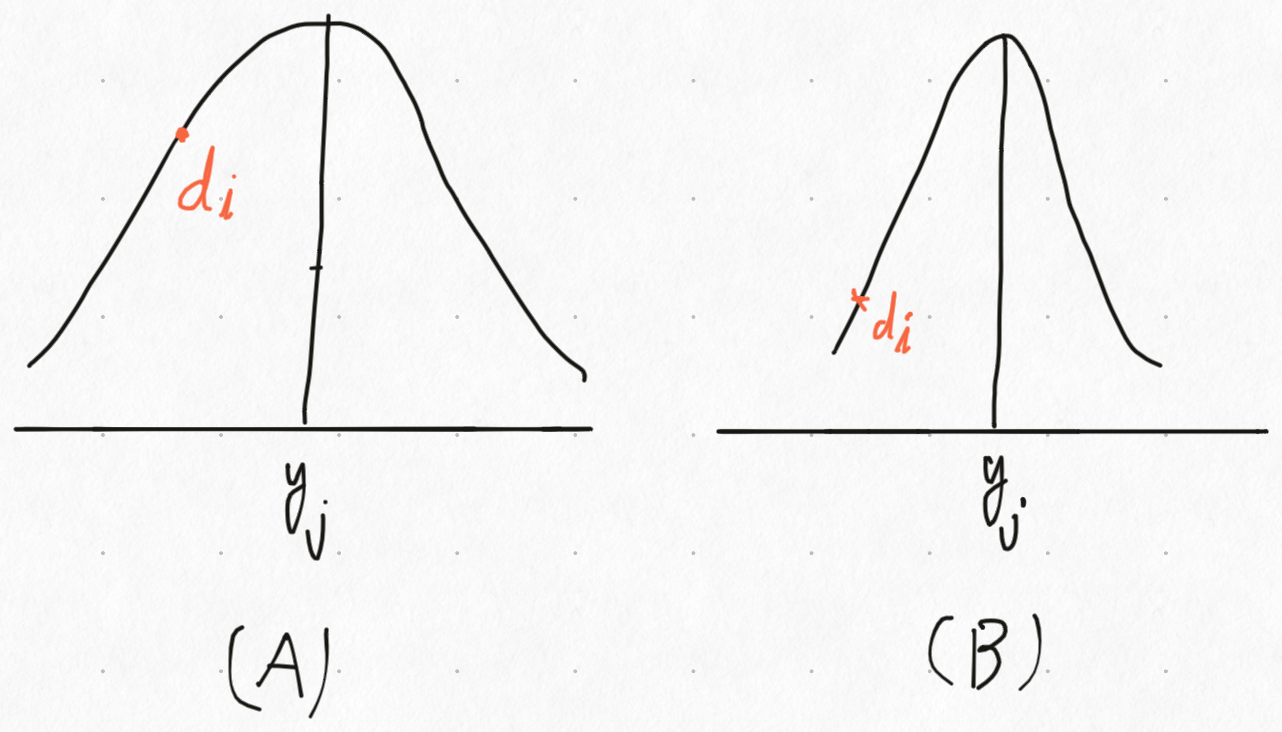
이미 알고 있겠지만 이 수식의 의미는 분산을 고려해 $d_{i}$와 $y_{j}$ 사이의 거리를 구한다는 의미로 불확실성의 정도를 거리에 반영한다는 의미이다. 이런 mahalanobis distance 의 단점은 분산이 커질 수록 서로 멀리 떨어져 있는 $d_{i}$와 $y_{j}$도 그럴 듯 한 값으로 해석한다는 것이다. Fig 4. (A), (B) 에서 $y_{j}$ 와 $d_{i}$ 의 거리는 실제로 같다. 다만 (A)는 분산이 크고 (B)는 분산이 작다. 이런 경우 mahalanobis distance 는 (A)에서 더 작다. 분산이 크기 때문에 (A) 분포 상에서 $d_{i}$ 가 더 나타날 확률이 높기 때문이다.
DeepSORT 에서는 mahalanobis distance에 mask를 씌우는데 특정값($t^{(1)}$) 이하인 경우만 고려하겠다는 의미이다. 논문에서는 이 마스크를 $b^{(1)}_{(i,j)}= I[d^{(1)}_{(i,j)} \le t^{(1)}]$ 라고 표현했다.
2. appearance descriptor(=embedding)
appearance descriptor는 occlusion, re-entering 가 발생했을 object나 camera의 motion이 클때 tracking 정확도를 향상시키기 위한 목적으로 추가되었다. (이 포스팅에서 appearance descriptor 는 appearance embedding 이라는 용어와 혼용해서 사용한다. 사실 appearance embedding 이 더 일반적인 용어인거 같긴하다.)
appearance descriptor는 Fig 3.에 나온것 처럼 detector 가 찾은 object 를 crop해 appearance embedding 을 추출하기 위해 별도의 CNN 에 입력으로 넣어 구한다. 각 track 은 최근 100 frame의 appearance embedding 을 유지한다.
appearance embedding 을 이용한 거리는 내적을 이용하고 아래와 같이 구한다.
$$d^{(2)}_{(i,j)}=min\{ 1-r^{T}_{(j)} \cdot r^{(i)}_{k} | r^{(i)}_{k} \in R_{k} \} $$
appearance distance도 특정 값($t^{(2)}$)을 이용해 마스킹 하고 논문에서는 이 마스크를 아래와 같이 표현한다.
$b^{(2)}_{(i,j)} = I[d^{(2)}_{(i,j)} \le t^{(2)}]$
cascase matching 알고리즘에서 최종 track-detection 간 matching 을 구하기 위해 사용하는 metric값은 아래와 같이 구한다.
$$ c_{(i,j)} = \lambda d^{(1)}_{(i,j}) + (1- \lambda ) d^{(2)}_{(i,j)} $$
아래는 cascade matching 알고리즘의 pseudo code 이다.

위 알고리즘은 1 부터 $A_{max}$ 까지 iteration 하면서 track-detection 쌍을 매칭한다. min_cost_matching 이라고 되어 있는건 hungarian algorithm 이라고 생각하면 된다.
iteration 을 하는 이유를 알기 위해선 $age$ 라는 변수를 설명 해야 한다.DeepSORT 에서 $age$ 는 가장 마지막으로 detection 된 프레임으로 부터 얼마나 오랫동안(몇 프레임이나) detection 과 매칭되지 않았는가 를 나타내는 변수이다. (track을 얼마나 오랫동안 유지 하느냐 인건데 occlusion, re-entering 시 ID-switching 을 예방하는데 도움이 된다.)
이 pseudo code에서 $A_{max}$ 가 $age$를 나타내는 값이다. $age$ 값이 작은 값을 가지는 track 부터 track-detection 간 매칭을 구하기 위해 사용하는데 $age$ 값이 작을 수록 kalman filter prediction 의 uncertainty(분산) 이 작으므로 이런 track 들에 detection 과 매칭될 기회를 먼저 주는 것이다.
이 단계에서 track-detection 간 match 된 object 들은 kalman filter update 단계로 입력된다.
matching되지 않은 것들은 unconfirmed 로 분류되어 iou matching 단계로 넘어 간다.
IoU matching
IoU matching 은 처음 detection 된 이후 3frame 이 안된(= 처음 detecion 된 이후 track-detection 간 매칭이 3번이 안된 object들) object들의 kalman filter prediction 값과 cascade matching에서 track-detection간 matching되지 않은 object들을 인풋으로 IoU 를 매트릭으로 SORT 와 같은 방식으로 matching 한다.
IoU matching 단계에서 track-detection 간 matching 된 object들은 kalman filter update 단계로 입력 되고
unmatched detection 은 새롭게 detection 된 object 라는 의미에서 3 연속 프레임 동안 detction 되기 전까지 tentative 상태로 track에 추가된다.
unmatched track의 경우 age > 30 이면 frame 에서 떠난 것으로 판단하고 삭제 하고 age <= 30 이면 track에 그냥 남겨 놓는다.
'Tracking' 카테고리의 다른 글
| [tracking] FairMOT (0) | 2023.01.08 |
|---|