
오늘은 리뷰할 논문은 FCOS: fully convolution one-stage detection 이다.
제목에서 알 수 있듯이 one-stage detector 이다.
Title: FCOS: Fully Convolution One-Stage Detection
link: https://arxiv.org/abs/1904.01355
FCOS: Fully Convolutional One-Stage Object Detection
We propose a fully convolutional one-stage object detector (FCOS) to solve object detection in a per-pixel prediction fashion, analogue to semantic segmentation. Almost all state-of-the-art object detectors such as RetinaNet, SSD, YOLOv3, and Faster R-CNN
arxiv.org
요약:
자세히 살펴 보기전에 FCOS의 컨셉을 간단히 요약 하자면 저자는 anchor-based one stage는 training 할때 anchor box overlab의 해결하는데 시간이 오래 걸리므로 anchor-box free한 detector를 제안한다. Anchor box를 제거한 detector에서는 low recall rate, ambiguous sample 문제가 발생할 수 있는데 이런 문제를 해결할 수 있는 구조를 제안하고 해당 구조에 대한 효율성을 실험을 통해 입증했다. (문제를 해결하는데 사용한 개념은 FPN(feature pyramid network, per-pixel estimation, center-ness 등으로 아래에서 자세히 살펴 본다.)
Contribution:
1. Detection 문제를 segmentation 문제 처럼 per-pixel prediction 문제로 정의 하고이에 대한 구조를 제안함
2. FCN(fully convolution network)을 사용해 문제를 해결함으로서 다양한 테크닉을 segmentation에서 사양하는 다양한 테크닉을 공유 해서 사용할 수 있다(고 주장함)
3. proposal free, anchor free 하게 문제를 정의 함으로써 hyper paramter의 개수를 줄임(사람에 대한 의존성을 줄인것이므로 이건 확실한 기여점이라고 개인적으로 생각한다.)
4. anchor box와 관련된 연산 감소(anchor box-GT box간의 매칭등에 소요 되는 연산량 감소)
5. One-stage로서 SOTA(state-of-the-art) performance를 이뤘고 2 stage detector에서 RPN으로 사용해도 anchor-based RPN보다 성능이 좋다.
6. 확장 가능한 모델이다.(이 논문에서는 Detection 문제가 타겠이었지만 instance segmentation, key-point detection 등으로 쉽게 확장 가능 하다(고 주장한다.). FCN base 이므로 이 말을 맞는 말일거 같다.)
Anchor-based detector의 문제 점들
Anchor-based detector가 가지는 문제는 크게 hyper parameter에 관련된 문제, negative-positive sample의 imbalance에 대한 문제, computation(연산량) 문제로 나눠 생각 할수 있다.
1. hyper parameter 관련 문제
- anchor의 수, 사이즈, aspect ratio등은 predefined되어 있는데 이에 따라 성능에 영향을 쉽게 받는다.(수작업으로 튜닝 해야 하는 파라미터의 개수가 많다)
- box scale과 aspect ratio가 고정이라서 다양한 모양을 가지는 small object에는 태생적으로 비효율 적이다.
2. sample imbalance 문제
- High recall rate을 달성하기 위해선 anchor box를 dense하게 배치 해야 하는데 이경우 많은 anchor box가 negative sample로 label되고 이는 학습 중 negative-positive sample 불균형을 악화 시킨다.
3. 연산량 문제
- anchor box는 IOU계산을 위해 predicted box-GT box간에 매칭을 해야 하는데 이때 발생하는 연산량이 비효율 적으로 많다.
기존 Anchor free detector들이 가지고 있던 문제 점들
1. YOLO1은 낮은 recall rate을 보여 주는데 이건 object center 근처에 있는 몇몇 points들만 bbox 예측에 이용했기 때문이다. (object를 감싸는 bbox내에는 굉장히 많은 point가 있는데 그중 center 근처의 몇몇 개만 이용하는게 문제라고 주장함)
2. CornerNet에서는 같은 instance에 속한 left-top, right-bottom corner pair를 찾기 위한 추가 metric을 학습하고 post processing을 이용해 이들을 grouping 하므로 연산량이 많아져 비효율 적이다.
3. Dense Box 기반의 모델들은 overlapping bbox, 낮은 recall rate등의 문제로 인해 일반적인 object detection task에 부적합 하다고 여겨졌다.
FCOS의 전략
본 논문에서는 위에서 언급된 anchor free detector들이 가지고 있는 문제들을 per-pixel prediction과 FPN을 이용해 해결하고, 제안하는 구조에서 발생한 low quality bbox prediction문제를 해결하기 위해 center-ness score layer를 도입했다.
1. Per-Pixel prediction
- Anchor-based detector 들은 feature map의 각 픽셀 위치를 object center라고 가정하고 미리 정한 size의 box를 regression 한다. 이중 IoU가 낮은 bbox들은 negative sample이므로 실질적으로 학습과정에서 object의 위치를 추정하는데 사용되는 픽셀은 object center 근처에 있는 픽셀들이 전부라고 할 수 있다.
저자는 이게 문제라고 생각하고 FCOS에서는 feature map의 모든 픽셀 위치에서 해당 픽셀이 특정 object에 속한 픽셀인지 아닌지, object에 속한 픽셀이라면 해당 픽셀에서 예상한 bbox는 무엇인지를 계산하는 방식이다.
예를 들어 아래 그림이 feature map이라고 한면 이 논문이 제안하는 방식은 p1,p2,p3 및 노란박스 영역에 속한 모든 pixel들은 노란박스가 나타내는 object에 해당 하는 픽셀이므로 해당 픽셀들 각각에 대해 (마치 sementic segmentation과 같이)픽셀이 속한 class label을 예측하고, 각 위치에서 object bbox를 regression한다.

이런 방식으로 feature map의 모든 픽셀에 대해(Fig1에서는 $p_{1},p_{2},...,p_{n}$ 전부에 대해) 해당 픽셀이 속한 class $c^{(i)}$, bbox 추측을 위한 4개의 값 $(l^{*},t^{*}, r^{*}, b^{*})$을 추정하도록 네트워크를 구성했다. 그러니까 한 픽셀당 $ (l,t,r,b,c)$ 5개의 값을 예측 하는 것이다.
이때 feature map 상의 픽셀 $(x,y)$가 라벨이 $c^{*}$인 object bbox 내부에 있는 픽셀이면 target label은 $c^{*}$로 정의 하고 positive sample이라고 보며 object bbox내부에 있는 픽셀이 아니라면 target label $c^{*} =0$ 이 되어 negative sample 로 정의 한다.
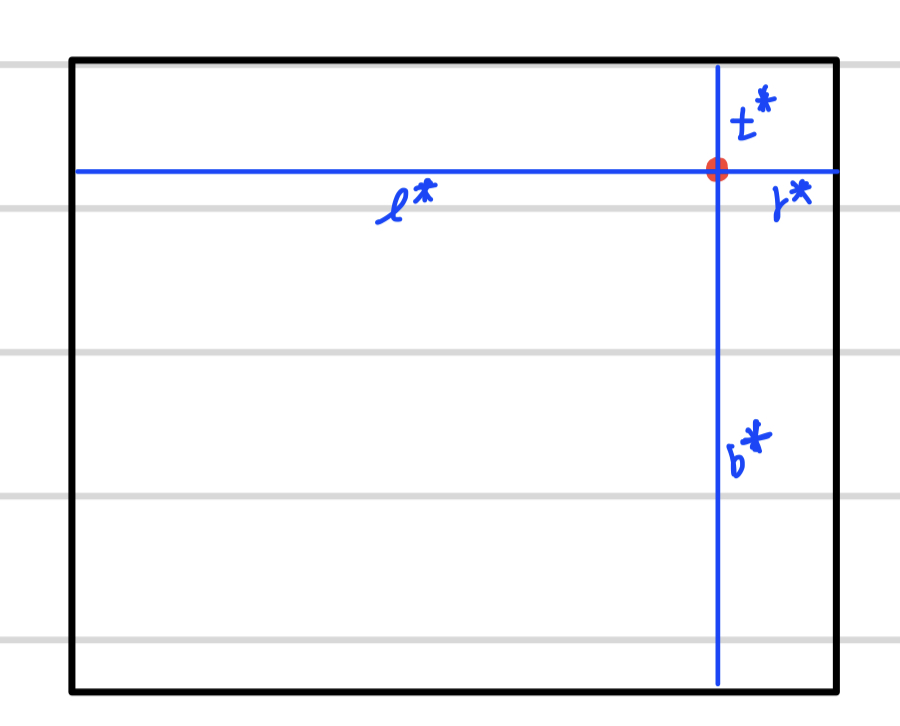
bbox 예측에 사용되는 target $(l^{*},t^{*}, r^{*}, b^{*})$ 각각은 feature map상의 위치 $(x,y)$에 대해 해당 픽셀이 포함된 object bbox의 $(좌측 면, 위쪽 면, 오른쪽 면, 아래쪽 면)$ 까지의 거리(단위pixel)에 해당하는 값으로 각각은 GT bbox 정보로 부터 아래와 같이 계산된다.
$$ l^{*}=x-x_{0}^{(i)}, t^{*}=y-y_{0}^{(i)}, r^{*}=x_{1}^{(i)}-x, b^{*}=y_{1}^{(i)}-y Eq(1)$$
위 식에서 $(x,y)$는 feature map 상의 위치, $(x_{0}^{(i)},y_{0}^{(i)})$는 object bbox의 left-top corner 좌표, $(x_{1}^{(i)},y_{1}^{(i)})$는 object bbox의 right-bottom corner 좌표를 의미 한다.
$(l,t, r, b)$를 network에서 예측 한 후 IoU를 계한 하기 위한 $(x_{0}^{(i)},y_{0}^{(i)},x_{1}^{(i)},y_{1}^{(i)})$복원은 $Eq(1)$이용해 쉽게 가능하다.
각 기호에 대한 정확한 의미는 아래 그림(Fig2.)를 참조 하면 더 직관적이다.

특이하다고 생각 한 점은 각 픽셀의 class label $c$를 추측 하기 위해 multi class classification 컨셉을 사용 하지 않고 각 object class별로 binary classification으로 학습했다는 것이다.
무슨 말이냐면 예를 들어 MS coco data 의 경우 object 카테고리가 80개 있다고 하면 class inference를 위한 network output은 총 80개의 channel로 구성될 것이다. 이때 channel 0은 vehicle, channel 1은 pedestrian, channel 2는 의자 등등이라면 임의의 $(x,y)$ 픽셀이 class 0 일 확률, class 1일 확률, class 2 일 확률을 채널축을 softmax를 취해 구하는 방식이 아니고, 각 channel을 별개로 보고 channel 0 에서는 vehicle에 속한 pixel과 그렇지 않은 pixel, channel 1 에서는 pedestrian에 속한 픽셀과 그렇지 않은 픽셀등을 각 채널 마다 binary classification loss를 구했다는 얘기이다.
참조: bbox regression을 할떄 네트워크에서 추측한 $(l,t, r, b)$는 target 인 $(l^{*},t^{*}, r^{*}, b^{*})$ 을 regression 하는데 바로 사용되지 않고 실제로 $exp^{(s_{i}l)}$로 사용 되는데 이는 network에서 나오는 $(l,t,r,b)$이 큰 값을 갖게 하고 싶지 않아서 사용 하는 테크닉으로 $(l,t,r,b)$가 상대적으로 작은 값이어도 $exp^{(s_{i}l)}$은 큰 값이 되서 비교적 scale이 큰 $l^{*}$을 추정 할수 있기 때문이라고 한다.
Loss function:

$L_{cls}$는 $focal loss$, $L_{reg})는 $IoU$ loss를 사용 했다. $N_{pos}$는 positive sample 수이다.
본 논문에서 $\lambda=1$로 세팅했다.
2. Multi-level Prediction with FPN
이 논문에서 제안하는 FPN의 구조는 아래와 같다.
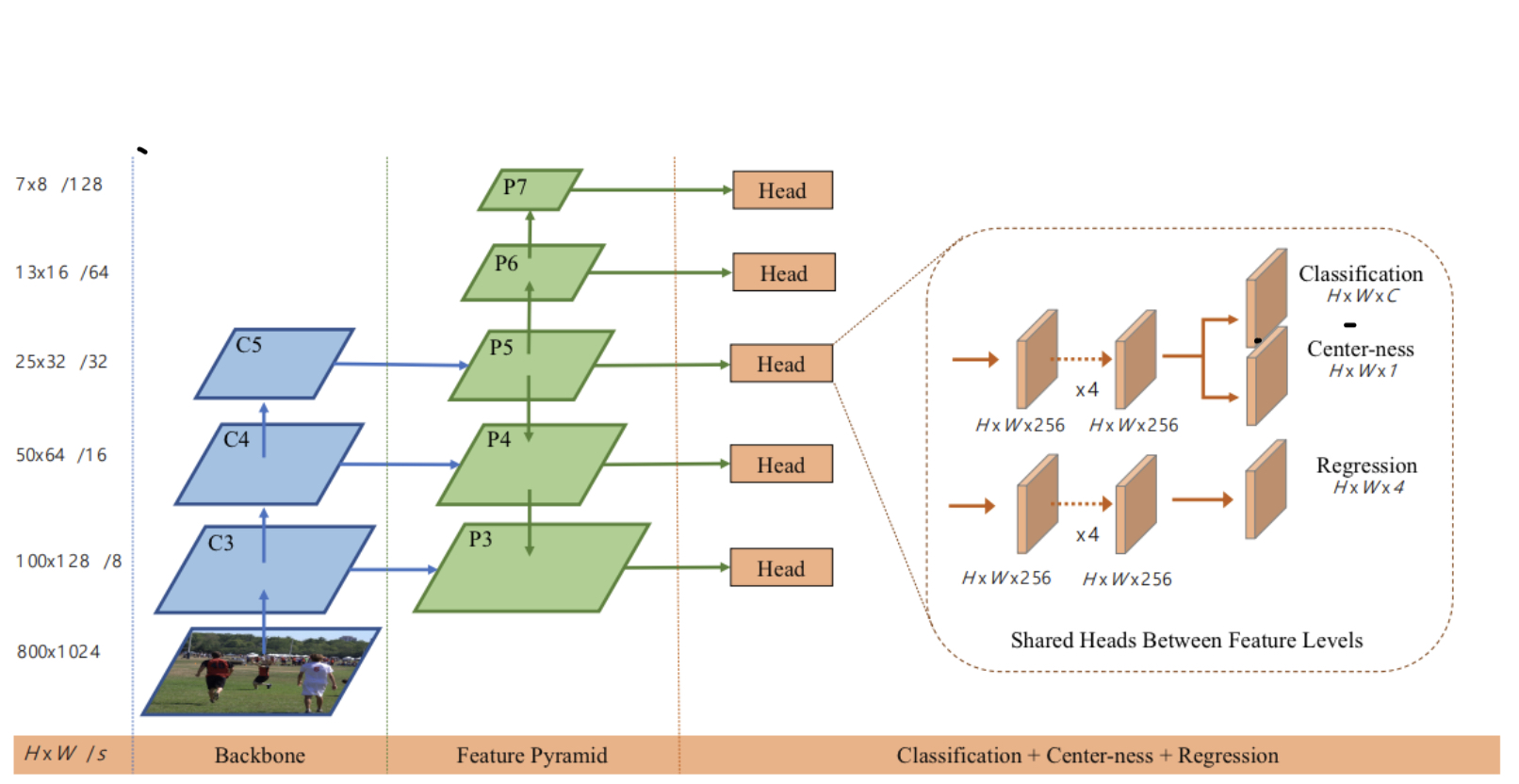
FPN(feature pyramid network)은 아래와 같은 FCOS의 weak point를 개선한다.
weak point 1: final feature map 이 큰 output stride를 가질때, 작은 물체들은 해당 feature map에서 표현이 안될 수 있어서 찾는게 불가능 하므로 recall을 낮게 만드는 원인이 된다.
weak point2: GT bbox 가 겹칠 경우 (Fig2. 오른쪽 overlapped region 참조) "overlap된 구간에있는 pixel들은 어떤 겹쳐진 두 bbox에 둘다 속하는데 어느 object의 bbox와 class를 타겟으로 학습해야 하는가?" 에 대한 문제가 생김
FPN을 이용 하면 서로 다른 size의 feature map을 만들 수 있는데 각 feature map에서 서로 다른 크기의 물체를 찾으면 위 약점들을 해결할 수 있다.
weak point 1 해결되는 이유: FPN에서 생성되는 feature map은 서로 다른 output stride를 가지므로 작은 output stride를 가지는 feature map에서 작은 물체를 찾고, 큰 output stride를 가지는 feature map에서
큰 물체를 찾으면 해결가능
weak point 2 해결되는 이유: 저자의 관찰에 따르면 overlap은 대부분 bbox의 크기 차이가 상당한 object들간에 발생하는 경우가 대부분이라고 한다. 따라서 overlap을 생성하는 겹쳐진 물체는 서로 다른 feature map에서 찾게 끔 되므로 overlap 문제를 상당부분 해결 할 수 있다. (예를 들면 Fig2. 오른 쪽에서 사람은 feature map P3에서 찾게 끔 할당되고 테니스 라켓을 P5에서 찾게 끔 할당되게 된다는 의미이다.)
정리하자면 Fig. 4 의 feature map $P_{3},P_{4},P_{5},P_{6},P_{7}$ 각각에서 찾아야 하는 object의 크기를 제안해 놓고 각 feature map에서 찾아야 하는 크기에 해당하는 object만 해당 feature map에서 detection된 object의 positive sample로 사용 하는 것이다.
이걸 정리하자면 $i ={ 3,4,5,6,7}$ 이 feature map $P_{i}$의 레벨을 표현할때 각 $P_{i}$에서는 아래 조건에 해당하는 크기의 object를 positive sample로 학습하도록 한 것이다.
$$m_{i-1} \leq max(l^{*},t^{*},r^{*},b^{*}) \leq m_{i}$$
논문에서 실제로 사용한 $m$ 값은 $\{m_{2},m_{3},m_{4},m_{5},m_{6},m_{7}\} =\{0,64,128,256,512, \infty\}$ 이다.
3. Center-ness
FPN을 이용하고도 FCOS는 anchor based detector들 보다 성능이 떨어졌는데 이 원인은 object center에서 멀리 떨어진 location에서 bbox prediction이 좋지 않아서 였다. 예를 들자면 아래 Fig.5 에서 붉은 점 위치의 pixel에서 검은색에 해당 하는 bbox를 regression 할때 그 예측값 $(l,t,r,b)$가 썩 좋지 않다는 것이다.
이런 문제를 해결하기 위해 object의 bbox를 결정할때 object center에서 멀리 떨어진 위치에서 예측된 값들의 영향성을 줄이기 위해 아래와 같이 center-ness 를 예측하는 layer를 추가해 이문제를 해결했다.
center-ness는 Fig4에서 보면 알수 있듯이 classification output과 같은 head에서 계산된다.
$$ center-ness^{*} = \sqrt{\frac{min(l^{*},r^{*})}{max(l^{*},r^{*})} \times \frac{min(t^{*},b^{*})}{max(t^{*},b^{*})}} $$
이렇게 계산된 center-ness의 heatmap은 아래와 같다.

실험:
Setting:
backbone: resnet-50
weight initialization: pretrained with imagenet (newly added layer: same as RetinaNet)
batch:16
optimizer: SGD
initial learning rate: 0.01, 0.001, 0.0001( 0.001, 0.0001은 각각 60k, 80k iteration에서 적용함)
input image size: $max(h,w) \leq 1333$, $min(h,w) \leq 800$

BPR성능:
Anchor based detector에 비해 BPR(best possible recall)이 낮을 것이라는 예상과 다르게 FCOS는 Fig7.의 table 1에 보이듯 $P_{4}$feature map 만 사용 한경우에서 조차 95.55%의 recall rate을 보여준다.
FPN을 사용 하면 98.4%로 $IoU \geq 0.4$ 인 경우만 고려했을 경우 Anchor base detector인 RetinaNet(with FPN)보다 훨씬 높고 모든 예측된 bbox를 다사용 한 RetinaNet(99.23%)비견될만 하다.
Ambiguous Samples 에 대한 성능:
Fig7의 Table 2에서 보면 minival에서 FPN을 사용 하지 않고 feature map $P_{4}$만 사용 할 경우 $ \frac{ambiguous samples}{all positive sample} = 23.16%$이지만 FPN을 사용할 경우 \frac{ambiguous samples}{all positive sample} =7.14%$로 줄어든다(개인 적인 생각은 FPN이 FCOS에서 효과적으로 ambiguous samples문제를 해결한다는 것을 보여주기에 이결과만으로 충분하다고 생각한다..)
이 결과는 저자의 관찰결과(= 대부분의 overlap은 크기 차이가 상단한 object들 사이에 발생하므로 FPN을 사용해 서로 다른 level의 feature map에서 찾게 하면 해결이 가능하다)가 설득력 있다는 근거가 될수 있다.
저자의 주장에 따르면 overlap이 같은 category에 속한 object들 사이에 일어나는 경우는 ambiguous location에 속한 픽셀(receptive field라고 생각하는게 더 정확할거 같다..)들은 어차피 class label이 같아 overlap에 관여하는 object중 어떤 object를 추정해도 성능 하락에 영향이 없으니 이런 경우를 배제 하면 $ \frac{ambiguous samples}{all positive sample} $은 Fig7의 Table 2의 Amb. samples(diff)(%)의 결과를 얻을 수 있다.(배제 한다는 것은 overlap이 서로 다른 category에 속한 object들에 의해 만들어지는 경우만 고려한다는 뜻이다.)
이럴 경우 FPN사용시 \frac{ambiguous samples}{all positive sample} =3.75%$ 까지 하락한다.
(추가 적으로 실제 inference할때 ambiguous location에서 생성된 bbox의 비율을 살펴 보면 2.5%의 bbox만이 이 overlapped location에서 생성되었고 그중 서로 다른 category가 overlap된 경우는 1.5%였다고 한다. 즉, 저자가 말하고자 하는 위와 같은 자신의 주장은 타당하나는 것....)
Centerness 의 효용성:

Fig 8 은 centerness를 사용할 때와 그렇지 않을때 의 성능을 보여준다. 직관적으로 알 수 있듯이 결론은 사용하는게 성능 향상에 더 좋다. 다만 $center-ness^{+}$의 경우 center-ness를 Fig 4의 Regression branch 에서 학습 시켰을 경우의 결과 이고, $center-ness$ 는 Fig 4에서 처럼 classification branch에서 학습 시켰을 경우의 결과 이다.
FCOS vs Anchor based detector:
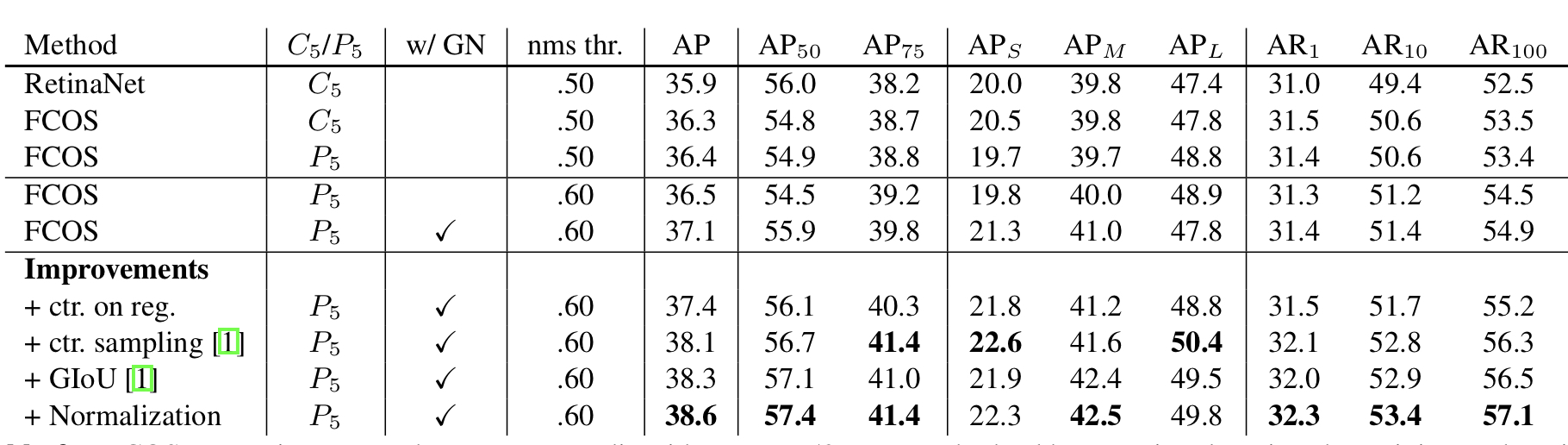
Fig 9 은 anchor based detector 인 RetinaNet과의 비교이다. 위표는 FCOS와 RetinaNet과의 차이를 최대한 배제한 상태의 실험 결과이다.(FCOS를 설계 할때 기존 RetinaNet에서 사용 하지 않은 Group Normalization(GN)을 사용 하고, FPN을 생성할때 Fig 4에서 $P_{5}$를 사용했는데 RetinaNet에서는 $C_{5}$를 사용해 $P_{6}, P_{7}$을 만들었다는 차이가 있는데 위의 실험 결과는 FCOS에서 GN사용 배제, $P_{6}, P_{7}$ 생성시 $C_{5}$사용등 조건을 최대한 똑같이 맞췄다는 것이다.)
결과는 보는데로 비등하거나 FCOS가 더 좋다. Improvement는 논문 제출 이후 개선한 버전에 대한 결과 값이다.
참고로 위 결과를 얻기 위해 FCOS는 RetinaNet을 학습할때 사용했던 Hyperparameter를 그대로 사용했다고 하는데 Hyperparameter는 해당 model에 최적화 해서 사용 하므로 FCOS에 더 잘맞는 hyperparameter를 사용할 경우 성능은 더욱 좋아 질 수 있을 거라고 한다.
(원래 논문에는 region proposal에 사용했을 때 어떤지에 대한 실험도 있는데... 그건 나중에 정리하도록 하자...)
'Deeplearning > paperReviews' 카테고리의 다른 글
| [논문정리] swin transformer (7) | 2022.01.04 |
|---|---|
| [논문 정리]CoordConv: An intriguing failing of convolution neural networks and the CoordConv solution 리뷰 (0) | 2021.08.10 |
| [InstanceSegmentation] SOLO:Segmenting Objects by Locations 논문 정리 (0) | 2021.08.08 |
| [AutoML] AttendNets 논문리뷰 (0) | 2021.05.19 |
| [object detection] CenterNet (Objects as points) 논문 리뷰 (0) | 2021.03.30 |