이전 글 [Deskew for ocr] Rotation correction 에서 regression으로 회전된 문서를 바로잡는 방식을 시도해봤다.
이전 글에서 쓴 모델의 문제는 크게 2가지
1. 회전되지 않는 문서를 회전된 문서로 오인식해 오히려 이상하게 회전시키는 문제가 발생한다.
2. 정확도가 굉장히 떨어진다.
이를 해결하기 위해 새로운 방식을 조사, 적용 했고 결과가 좋아서 공유한다.
이번엔 회전된 문서를 바로잡는 문제를 분류 문제로 정의 하고 해결해 본다. 이 방식은 ocropus3 를 참고 했다.
코드는 아래 링크의 devStream_fft branch 에 있다.
link: https://github.com/pajamacoders/ocrDeskew/tree/devStream_fft
문제 정의
문서가 얼마나 회전되어있는 지를 분류 문제로 정의 하고 풀기 위해서 각 회전의 정도에 class를 부여 해야 한다.
나는 0.5도 단위를 하나의 클래스로 정의했다.
예를 들자면 아래와 같은 방식이다. 문서가 회전된 각도를 degree 라고 표현 했을 때 회전의 정도(degree) 가 -1 도에서 -0.5 도 이내이면 class 0에 배정 하는 방식이다.
| range | -1< degree<-0.5 | -0.5<= degree <0 | 0<= degree <0.5 |
| class | 0 | 1 | 2 |
이러한 방식으로 -89~89도 사이에서 회전된 문서의 rotation correction 문제는
356 클래스를 가지는 분류 문제로 정의 할 수 있다.
개발 환경
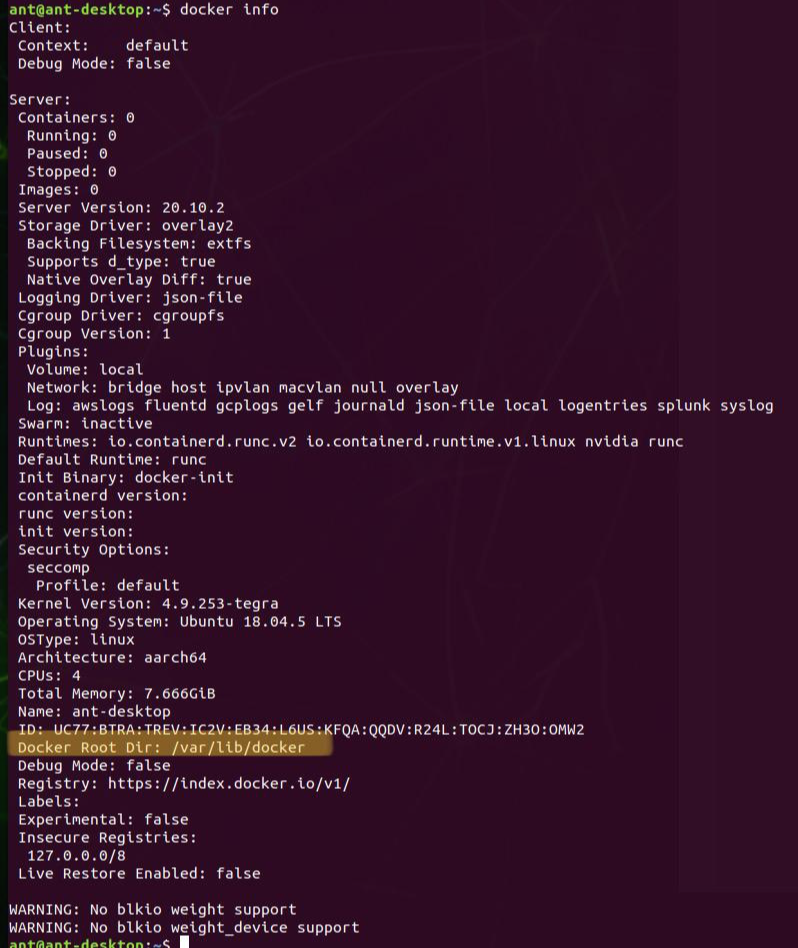
개발 환경은 ngc repo에서 아래 이미지를 다운 받았다.
docker image : nvcr.io/nvidia/pytorch:22.01-py3
train metric tracking: mlflow
전처리
전처리 과정은 이전 글 [Deskew for ocr] Rotation correction 의 전처리와 거의 유사하지만 rotation의 정도에 class를 대응 하는 부분만 차이가 있다.
이전 글에서 바뀐 GT 생성 부분인 RandomRotation class 는 아래와 같다.
class RandomRotation(object):
def __init__(self, ratio, degree, buckets=None):
self.variant = eval(degree) if isinstance(degree, str) else degree
self.ratio = eval(ratio) if isinstance(ratio, str) else ratio
self.buckets = eval(buckets) if isinstance(buckets, str) else buckets
def __call__(self, inp):
if np.random.rand()<self.ratio:
deg = np.random.uniform(-self.variant, self.variant-0.1)
img = inp['img']
h,w= img.shape
matrix = cv2.getRotationMatrix2D((w/2, h/2), deg, 1)
dst = cv2.warpAffine(img, matrix, (w, h),borderValue=0)
inp['img'] = dst
else:
deg = 0
if self.buckets:
rad = np.deg2rad(deg)
range_rad = np.deg2rad(self.variant)
bucket = int(self.buckets * (rad+range_rad) / (2*range_rad))
inp['rot_id'] = bucket # 이 값이 문서가 회전된 정도를 class에 할당 한 값 즉 target class 값이다.
inp['degree'] = deg
return inp
모델
이번 모델의 특이점은 중간에 fft를 사용 하는 layer 가 들어간다는 것이다.
모델은 아래와 같다.
class DeskewNetV4(nn.Module):
def __init__(self, buckets, last_fc_in_ch, pretrained=None):
super(DeskewNetV4, self).__init__()
buckets = eval(buckets) if isinstance(buckets, str) else buckets
assert isinstance(buckets, int), 'buckets must be type int'
k=5
self.block1 = nn.Sequential(
ConvBnRelu(1,8,k,padding=k//2),
nn.MaxPool2d(2,2), #256x256
ConvBnRelu(8,16,k,padding=k//2),
nn.MaxPool2d(2,2), #128x128
)
self.block2 = ConvBnRelu(16,8,k,padding=k//2)
self.fc = nn.Sequential(nn.Linear(131072,last_fc_in_ch, bias=False),
nn.BatchNorm1d(last_fc_in_ch),
nn.ReLU(True),
nn.Linear(last_fc_in_ch, buckets, bias=False))
self.__init_weight()
if pretrained:
self.load_weight(pretrained)
def forward(self, x):
out = self.block1(x)
out = torch.fft.fft2(out)
out = out.real**2+out.imag**2
out = torch.log(1.0+out)
out = self.block2(out)
bs,c,h,w = out.shape
out = out.reshape(bs,-1)
out = self.fc(out)
return out
결과
모델의 last_fc_in_ch의 값으로 128을 사용 할 경우 아래와 같은 결과를 얻었다.
학습은 총 800에폭을 돌렸는데 굳이 이럴 필요까진 없었다.
optimizer로 adam을 사용 했고 lr_schedule은 cosineannealing을 lr range 1e-3 ~1e-6으로 사용 했다.
ce_loss:0.1241
precision:0.9466
recall:0.9426
f1_score:0.9427
아래는 train, validation 시의 f1 score의 값을 나타낸 그래프 이다.
200epoch 쯤 되면 성능 향상은 거의 없는 것을 볼 수 있다.

아래 그림은 임의의 숫자를 적은 문서로 테스트 한 결과 이다.
왼쪽이 입력으로 들어간 회전된 문서이고 오른쪽인 inference로 회전을 바로잡은 결과이다.
regression 모델 보다는 전체적인 결과가 훨씬 좋다.

- 끝 -
'Deeplearning > toyproject' 카테고리의 다른 글
| [head pose] head pose 를 이용한 gaze estimation 및 불확실성(uncertainty) 추정 (0) | 2022.06.28 |
|---|---|
| [Deskew for ocr] Rotation correction (0) | 2022.02.15 |