os 설치를 위한 가이드도 여기에 잘 설명 되어있으니 잘 따라 하면 된다. 나도 가이드를 따라 Etcher를 이용해 SD 카드에 os를 설치 했다. Etcher를 실행 하면 다음과 같은 화면이 나오는데 이때 Flash from File을 선택해서 search window가 나오면 위의 os download page에서 받은 os파일을 선택한다.
Fig 3 Etcher 실행화면
이 후 target device 선택에서 os를 구울 SD 카드를 선택하고 Flash! 를 누르면 아래와 같이 os 설치가 시작된다.
Fig 4. OS 설치 중인 화면
설치가 다되면 Fig 7 의 붉은 색 동그라미 부분에 sd를 삽입한다.
조립
1. 우선 케이스에 메인 전원/ 리셋 버튼을 아래와 같이 연결한다. LED 선이 있는 큰 버튼이 메인 전원선이고 작은게 리셋 버튼인다.
Fig 5. 전원 및 리셋 선 버튼 연결 모습
2. 다음으로 팬을 팬을 연결한다. 팬의 전원은 아래 그림 Fig 6 처럼 랜선 연결 소켓과 방열판 사이의 4핀에 연결 하면 된다. 다음으로 구성품에 있는 나사와 너트를 이용해 방연판위에 팬을 설치 한다. 그냥 나사만 꽂으면 고정이 절대 안되고 나사 구멍이 잇는 방연판 밑에서 너트로 고정 시켜 줘야 한다. 이때 구성품의 필셋이 유용하게 씌인다. 팬을 단 모습은 Fig 7에 있다.
Fig 6 팬 전원 연결 모습Fig 7 팬 고정 모습
3. 다음으로 무선 랜카드 및 안테나는 연결 한다. 아래 그림 Fig 8이 안테나와 안테나-무선 랜카드 연결선을 보여 준다. 안테나 선을 케이스에 Fig 9처럼 연결하고 반대쪽 끝부분은 랜카드에 “똑” 소리가 나도록 확실히 연결 해 준다. 연결해야 하는 곳은 Fig 9의 붉은색 동그라이로 표시했다. 연결을 마쳤으면 보드에 해당 랜카드를 꽂아야 하는데 이 부분이 좀 불편하다. Fig 7에 녹색으로 표시한 “고정나사”를 풀고 코어보드(방열판이 붙어 있는 보드)를 잡고 있는 해치를 풀면 Fig 10과 같은 모습이 된다. Fig 10의 표시 부분에 랜카드를 삽입후 나사로 고정하고 다시 코어 보드를 다시 연결하고 “고정나사”를 체결 한다. (생각해보면 방열판에 팬을 연결하기 전에 이 작업 부터 했으면 편했을거 같다.)
Fig 8 wifi 안테나와 무선 랜카드 연결 선Fig 9 안테나와 무선 랜 카드 연결 모습Fig 10 랜 카드 연결 부위 및 순서, 전원, reset 버튼, LED 전원 연결 위치
4. 전원 및 리셋 선 메인보드에 연결. Fig 10에 노란 색으로 전원, reset, 전원 LED라고 표시해 놓은 부분을 보자. 1단계 에서 케이스에 연결한 전원 버튼과 리셋 버튼에는 각각 4개, 2개의 커넥터가 있다. 이 커넥터 들을 각각 Fig 10에 노란색으로 표시한 부분에 연결 하면 된다. 좀더 설명하자면 전원 버튼의 붉은 선을 전원이라고 표시한 부분의 PWR BTN(메인 보드에 이렇게 써있다)에 연결하고 검은색 선을 GND에 연결한다. 다음으로 전원 버튼에 있는 흰색 선과 파란선은 LED 전원선인데 흰선을 LED +, 파란 선을 LED-에 연결한다. 리셋 버튼의 붉은색 선은 SYS RST에 검은 선은 GND에 연결 하면 된다. 모두 연결한 모습이 아래 그림 Fig 11에 있다.
Fig 11 전원 및 리셋 버튼 선 연결 모습
보드를 케이스에 고정시키고 조립을 마치면 아래와 같은 모습이 된다.
Fig 12 조립 완료 모습
참고: 연결을 하고 부팅하면 쿨러가 움직이지 않아 고민을 했는데 부팅 후 쿨러 control configuration 을 수정해 수동으로 쿨러를 조정 할 수 있다. 하지만 테스트 cuda프로그램을 돌려본 결과 gpu사용시 코어 온도가 올라가면 자동으로 쿨러가 동작하는 걸 봐선 그냥 둬도 필요시 알아서 동작하는거 같다.
오늘 정리할 논문은 swin transformer로 요즘( 혹은 한동안) 핫한 transformer를 비전 테스크에 적용한 논문이다. 기존 CNN 기반의 backbone을 사용하지 않고 순수하게 transformer를 이용해 feature를 이미지에서 feature를 뽑아 낼 수 있다는 것을 보여준다.
Transformer는 NLP분야에서 LSTM을 대체 할 수 있는 방식으로 연구되다 비전쪽에서도 다양한 문제에 응용되고 있다. 하지만 텍스트와 영상은 그 특성이 서로 다르다. 구체 적으로 영상에 transformer를 적용하는 것에는 다음과 같은 문제를 해결해야 한다고 이 논문에서는 말하고 있고, 각각에 대한 본인들만의 해결책을 재시 했다.
1. word token과 달리 visual element는 scale이 다양하다. NLP를 정확히 몰라 이부분에 대한 내 이해가 정확한지는 모르겠지만 나름 해석을 해보자면 NLP에서 각 word token은 고정된 크기의 embedding으로 변환 된다. 하지만 이미지는 그 크기가(resolution이) 640x480, 1024X768등 다양할 수 있다. 따라서, 영상에서 NLP의 token과 같은 고정된 크기로 표현 가능한 단위를 설정하는게 필요하다. -> 일정 한 수의 pixel 집합을 patch라고 정의하고 이 patch를 token처럼 처리의 최소 단위로 정의해 이 문제를 해결
2. 영상은 텍스트에 비해 high resolution이다. semantic segmentation 같은 경우 pixel 단위의 prediction이 필요 한데 transformer의 computational complexity가 image size에 qudratic 하게 증가 하기 때문에 연산량 증가의 문제가 발생한다. -> 계층적인 feature map을 이용하고 feature map의 window 내에서 local self-attention을 적용함으로서 complexity 문제를 해결, 각 window에는 일정한 수의 patch 만 포함되도록 설계하여 전체 연산량이 window 수에 선형적으로 증가하게 설계(self-attention 계산 방식의 최적화)
3. self-attention을 ResNet의 spatial convolution 전체 또는 일부를 대체하는 방식이 제안된 적이 있으나 실제 하드웨어에서 latency issue가 발생한다( 이부분은 정확히 이해 하지 못했다. 언급된 방식들의 caching 능력이 떨어진다고 봐야 할 거 같은데... 혹 이 글을 읽고 있는 누군가 이에 대한 답을 안다면 댓글로 설명 좀 해주심이..) -> shift windows를 사용해 해결
즉 swin transformer 의 key feature는 1. shift window, hierahical patch representation(계층적 패치 표현), 최적화된 self-attention 계산 방식 으로 볼 수 있을거 같다.
구조
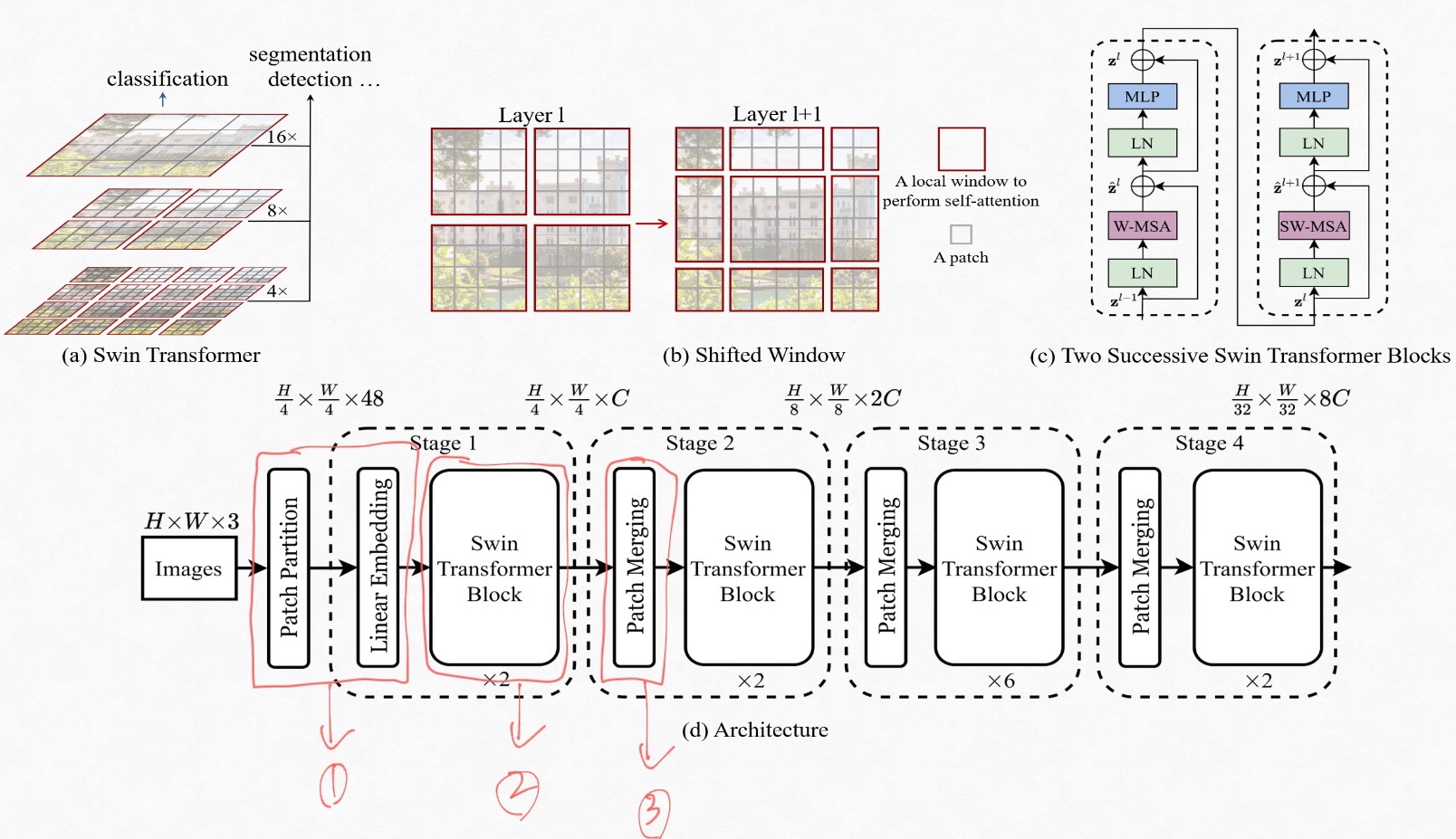
이제 swin transformer의 구조를 살펴 보자. 여기서는 아래 그림 Fig1 의 (d)의 전체 구조를 참고해 입력 영상이 각 모듈에 들어가서 연산을 거칠때 어떻게 변해 가는지 그리고 위의 contribution에서 언급한 각 문제점의 해결책이 어느 모듈에서 어떻게, 왜 수행되는지를 정리 할 것이다. 여기서는 숲을 설명하고 나무를 설명하는 방식이 아니라 각 모듈을 나무로 생각하고 나무에 대해서 설명한다. 각 모듈에 대한 설명을 이해하고 Fig1 (d)의 보면 전체적으로 이해 하는데 도움이 될 거라고 생각한다.
Fig1. Swin transformer 구조
Fig1은 swin transformer 의 계측적 구조, shift window, transformer block 내부 구조, 전체 모델의 구조를 보여 준다. 우선 (d)의 전체 구조를 기준으로 살펴 보자.
swin transformer에서는 patch 라는 단위를 NLP의 token 처럼 사용한다. 이 patch를 이용해 고정된 크기의 embedding을 만들어 낸다. patch 라는 용어가 새로 나와 겁먹을 필요는 전혀 없다. 입력 영상에서 4x4 윈도우 내에 들어오는 pixel들을 concat해서 표현한 것이 patch이다. 예를 들어 입력 영상을 HxWx3, patch 크기를 4x4 pixel로 정하면, patch partition은 4x4 크기의 grid셀에서 그룹을 형성하는 pixel들을
R
G
B
R
G
B
...
G
B
와 같이 concat해서 나타낸다. 이렇게 나타낸 patch는 4x4x3=48 의 크기를 지닌다. (4x4는 patch 크기 이고 3은 pixel의 channel 수 이다.) 이렇게 표현된 patch를 embedding으로 표현 하기 위해 linear layer를 이용해 연산한다.
아래 그림 Fig2는 Fig 1. (d)의 patch partition + linear embedding 모듈에서 입력 영상이 어떠한 형태로 변화 되는 지를 간단히 도식화 하고 있다. Fig2 의 가장 좌측 그림을 보면 굵은 선 안쪽에 얇은 선으로 4x4 필셀을 표현했다. 서로 다른 색으로 표혀한 것이 4x4 pixel 그룹이다. 이 4x4 픽셀들을 channel 축으로 concat하고 128channel의 embedding 을 만들기 위해 linear layer에 입력하고 swin transformer block에 입력하기 위해 spatial 축(영상의 가로와 세로) 를 HxW 으로 flatten 해주면 Fig 2의 가장 오른쪽같은 형태가 된다.
Fig 2. Patch partition + linear embedding 도식화
다음으로 swin transformer block에서는 multihead attention을 이용한 연산을 수행한다. 블럭 내에서 수행되는 연산은 Fig 1의 (c)를 보면 알 쉽게 알수 있다. (c)에서 W-MSA는 윈도우 내에서 수행되는 multi head self-attention을 의미한고 SW-MSA는 shifted window multi head self-attention을 의미한다.
swin transformer에서 self attention은 non-overlapped window내의 patch만을 이용해 수행된다. 여기서 윈도우란 patch의 집합으로 이해 하면된다. (patch는 인접 pixel의 집합, window는 인접 patch의 집합)
W-MSA와 SW-MSA가 있는 이유는 input의 크기에 quadratic 하게 증가하는 computational complexity 문제를 해결하기 위해 도입한 window라는 개념 때문이다. 윗 문장에서 말했듯 swin transformer에서 정의하는 윈도우는 non-overlap이다. 즉 윈도우 내에 속한 patch 들 간의 연관성은 self-attention에서 고려 할수 있지만 서로 다른 윈도우에 속한 patch들 간의 연관성을 파악할 수 없다는 문제가 생긴다. 이를 해결 하기 위해 도입된게 SW-MSA(shifted window multi head self-attention)이다. Fig 1.의 (b)가 W-MSA와 SW-MSA에서 feature map을 어떻게 나누는지 보여준다. 우선 Fig 1. (b)의 왼쪽 그림은 사이즈가 4x4인 non-overlapped window로 feature map을 나눴을 때의 경우를 보여 준다(W-MSA에서 연산에 이용하는 window partition 방식이다.) Fig 1. (b)의 오른 쪽 그림은 SW-MSA모듈에서 사용하는 window partition 방식으로 W-MSA에서 서로 다른 window에 속해 있던 patch들이 같은 window로 묶이면서 상호간의 연관성(self-attention)을 고려 할 수 있게 된다.
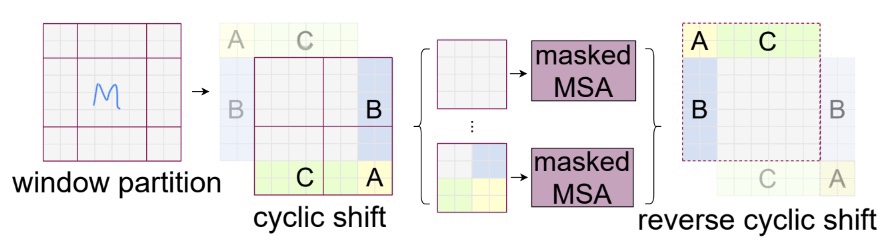
SW-MSA를 구현 할때 한 가지 중요한 아이디어가 들어가는데 바로 cyclic shifted window이다. window의 크기와 shifted window의 stride에 따라 영상의 가장자리에 patch들이 window를 가득 채우지 못 할 경우 이를 해결 하기 위해 feature map을 단순히 패딩 하면 연산량이 증가되는 손실을 감수해야 한다. 저자는 이러한 문제를 효율적으로 풀기 위해 feature map을 top-left 방향으로 shift 시켰다. 아래 그림 Fig 3은 이 방식을 도식화해 보여 준다.
Fig 3. cyclic shift 
Fig 3 의 가장 왼쪽은 partition 된 feature map을 보여주는데 정 중앙에 위치한 M이 속한 윈도우만 실제 윈도우 크기에 부합하고 나머진 partition들은 윈도우의 크기보다 작게 된다. 각 partition을 모두 패딩해서 윈도우 크기인 4x4로 채우는 대신 Fig 3 cyclic shift 에 나타낸 것 처럼 A,B,C를 top-left 방향으로 회전(cyclic shift) 시키면 패딩을 하지 않아도(실제 코드에서는 물론 패딩도 들어간다. 하지만 패딩의 크기는 최소화 된다.) window 크기에 딱 맞는 partition을 만들 수 있다. 단 이렇게 하면 A,B,C는 원래의 feature map 에서 실제로는 서로 이웃 하지 않은 patch들과 같은 window에 속해 self-attention이 계산되는데 cyclic shift 하기 전의 feature map에서 서로 이웃 한 patch들간에만 self-attention이 계산 되도록 mask를 씌워준다. 이렇게 SW-MSA 연산이 끝나면 cyclic shift했던 것을 되돌려 준다.
W-MSA, SW-MSA에서 또 한가지 언급 할 것은 Relative position bias이다. Attention module 에서는 Q⋅KT\sqrtd+B 와 같이 positional bias (B) 를 연산 과정에서 더 해준다. swin transformer에서는 relative position bias를 이용했는데 윈도우 크기를 M 이라 할때 한 윈도우의 각 축으로 방향으로 [−M+1,M−1]의 상대 위치 offset을 정의하고 이 값들로 B를 구성해 positional bias로 이용했다. (transformer에서 positional bias는 매우 중요한 개념이다. 여기선 간단히만 언급 했지만 사용 이유와 의미를 꼭 파악하자. 스스로에게 하는 말이다. )
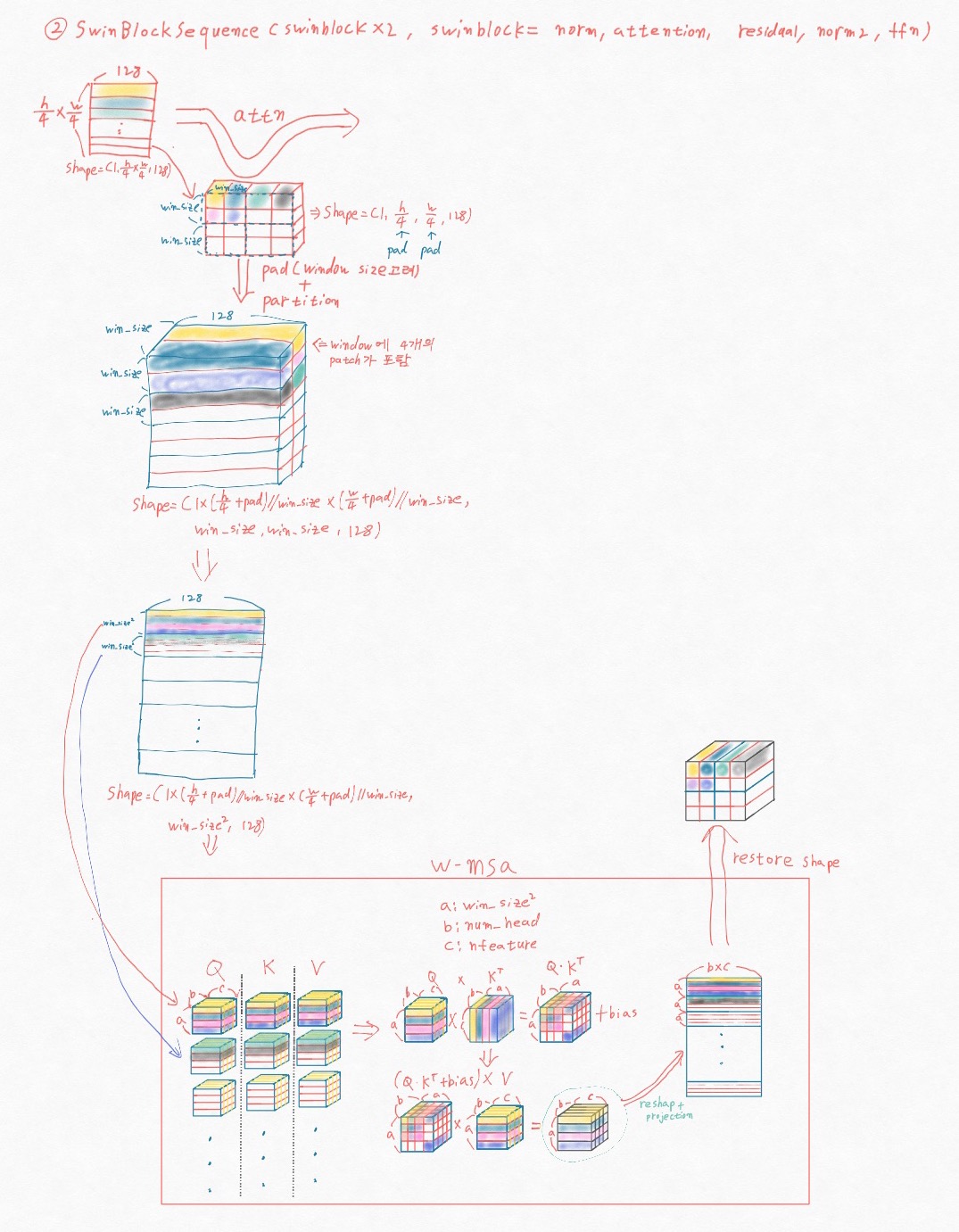
아래 Fig 4. 은 Fig 1. (d)의 swin transformer block에서 입력이 data가 어떤 모양으로 변하고 어떻게 연산되는지를 간략히 도식화 한 그림이다. patch partition + linear embedding 단계에서 flatten되었던 입력 영상을 non-overlapped window로 분리하기 이해 공간 정보를 복원한다.(공간 정보를 복원한다는건 입력의 shape을 (batch size, HxW, embedding size)에서 (batch size, H,W, embedding size)로 reshape 하는 과정을 말한다.) 그 후 윈도우 크기로 분해된 feature map을 W-MSA또는 SW-MSA의 입력으로 넣어 attention 을 계산 해 준다. 어텐션 과정도 내 나름대로 도식화 했지만 내가 보기에만 좋은 그림 같기도 하다. 혹시 self-attention 연산 과정을 정확히 알지 못하는 독자는 여기 를 참조 하길 추천한다. (나에겐 정말 큰 도움이 되었다.)
Fig 4. swin transformer block 내의 연산 과정 및 데이터 변화
그런데 왜 이렇게 window 개념을 도입하면 computational complexity가 줄어드는 걸까?
MSA 연산은 크게 다음과 같은 단계로 구성된다. -> 다음에 나오는 것은 각 단계에서 이루어지는 연산의 연산량이다.
1. input x와 weight WQ,WK,WV를 이용해 Q,K,V 계산
->Q=X⋅WQ=>(hw×C)×(C×C)=hw×C2
K=X⋅WK=>(hw×C)×(C×C)=hw×C2
V=X⋅WV=>(hw×C)×(C×C)=hw×C2
2. Q,K 를 이용해 attention score 구하기
->A=Q⋅KT=>(hw×C)×(C×hw)=(hw)2C
3. attention score와V를 이용해 값 정재
->Z=A⋅V=>(hw×hw)×(hw×C)=hw×C
4. attention 적용된 output Z에 output weight Wz 적용
->out=Z⋅Wz=>(hw×C)×(C×C)=hwC2
이렇게 각 단계의 연산량을 다 더하면 MSA의 연산량은 Ω(MSA)=4hwC2+2(hw)2C 이가 된다.
그럼 W-MSA 는 어떨까?
위에서 언급한 4단계에서 2, 3단계의 연산량이 아래와 같이 바뀐다.
2. Q,K 를 이용해 attention score 구하기-> attention score를 윈도우 MxM에서 구하기
-> attention score를 구할때 고려하는 patch수는 hw가 아니라 MxM 즉 M2
A=Q⋅KT=(M2×C)×(C×M2)=M4C
3. attention score와 V를 이용해 값 정재
-> Z=A⋅V=>(M2×M2)×(M2×C)=M4C
다만 윈도우가 ⌊hM⌋×⌊wM⌋ 개 있으므로
hwM2×2(M4)C=2M2hwC 가 된다.
따라서 window multi head self-attention을 적용하면 Ω(W−MSA)=4hwC2+2M2hwC 가 되어
M2<=hw 일경우 연산량이 적어진다.
마지막으로 계층적(hierachical feature)를 생성하기 위해서 patch merging 모듈에서는 patch의 숫자를 줄인다. 방식은 patch partition 에서 input의 RGB 채널은 concat한 것 처럼
각 stage의 출력을 patch mergin layer에서 2x2 grid 안에 들어오는 즉 서로 인접한 4개의 patch를 채널 축으로 concat 해준다.
이걸 convolution의 receptive field관점으로 해석 하면 stage 1에서 4x4 가 receptive field이고 stage2dptjsms 8x8, stage 3 에서는 16x16, stage 4에서는 32x32 와 같이 볼 수 있다. Fig 1의 (a)는 이것을 도식화 한 것이다.
Additive angular margin loss 는 metric learning에서 사용하는 loss로 ArcFace라는 논문에서 face recognition문제를 해결하기 위해 제안했다. 얼굴인식 문제를 풀기위해 제안되었을 뿐 similarity 문제를 푸는 대부분에 응용이 가능 하다.
목표는 triplet loss와 유사하게 (동작 방식은 전혀 다르다 목표만 유사하다) intra-loss는 감소 시켜 같은 클래스에 속한 입력들이 feature space에서 응집력을 가지게 학습시키고 inter-loss는 크게 해서 서로 다른 클래스에 속한 입력들은 feature space에서 구분가능한 만큼 떨어지게 학습시키는 것이다. 단 additive angular margin loss에서 의 거리는 Euclidian 거리가 아니라 loss의 이름에서 유추 가능 하듯 angular 거리 즉 각도의 차 이다. (왜 각도 차 인지 아래 '개념' 섹션을 참조하면 이해에 도움이 될 것 이다.)
- intra-loss: 같은 클래스에 속한 입력의 feature 들 간의 loss - inter-loss: 다른 클래스에 속한 입력의 feature 들 간의 loss
장점
softmax나 triplets loss 는 다음과 같은 문제를 가지고 있다. 1. softmax의 문제 - 분류해야하는 클래스의 개수가 증가 할 수록 fc 레이어의 아웃풋의 크기가 선형 증가 하게 되어있다. - 학습된 feature는 Closed-set(폐쇄형) 분류 문제에는 충분할 수 있지만 Open-set(개방형) 얼굴 인식 문제에 충분한 분별력을 갖지 못한다.(이건 논문에 써있는데 얼굴 인식 문제를 직접 풀어 본적이 없어서 실제로 그런지는 잘 모르겠다. ) 2. triplets loss의 문제 - triplets loss를 설명 할때 [주의사항]으로 써놓았는데 triplets은 (anchor, positive, negative) 3쌍의 sample이 필요하다. 입력의 class가 커지면 저 3쌍의 결합 개수는 폭발적으로 증가 할 수 있다. - semi-hard triplets 를 선택하는게 굉장히 힘들고 비용 소모가 크다.
고로 장점은 triplets loss 처럼 semi-hard 한 샘플을 신중하게 선택할 필요가 없으며 softmax 보다 더 분별력있는 feature를 학습 할수 있게 해준다. 아래 그림은 softmax와 additive angular margin loss를 이용해 학습한 feature를 2D 공간에 그린것이다. 이렇게 보면 softmax보다 additive angular margin loss가 훨씬 decision boundary가 명확해 보인다.
Fig 1. (좌) softmax를 이용해 학습한 feature의 2상에서의 분포, (우) additive angular margin loss를 이용해 학습한 feature의 2d 상에서의 분포
연산
Fig 2. additive angular margin loss
위 그림은 additive angular margin loss가 어떻게 동작하는지 보여준다.
classification 문제를 기준으로 설명 하자면 대부분의 DCNN(Deep Convolutional Neural Networks)모델의 마지막 레이어는 FC(fully connected) layer이다. 이 FC layer의 출력을 feature 라고 하고 기호로 x라 하자. (위 그림의 xi가 바로 이 feature이다.)
x∈Rd _(x가 d차원 상에 있다면)_ 라 하고 W∈Rdxn 이라 하자. 여기서 n 은 클래스의 개수 이다. (아래 저차원에서의 예를 들어 다시 설명할 것이다.) additive angular margin loss 의 입력으로 들어온 xi는 normalization 된 후 normalization 된 W와 메트릭스 곱 WTx연산을 한다. 우리는 WTx 연산을 W의 각 column에 해당하는 wjj∈(1,...,n) 벡터와 입력 x 벡터의 내적 연산 즉 wj⋅x으로 해석 할 수 있다. (wj 가 W의 column 벡터 이므로 Rd 상에 존재 하며 x와 차원이 같으므로 내적이 가능하다.)
내적연산이 →a⋅→b=|→a||→b|cosθ 임을 떠올려 보자.
우리의 상황에 적용하면 아래와 같이 된다. →wi⋅→x=|→wj||→x|cosθ 여기서 wi, x는 normalization 된상태 이니 |→wi|=1, |/vecx|=1 이다. 즉, wj⋅x=cosθ 이다.
wj⋅x=cosθ 의 값을 acos에 대입하면 θ를 구할 수 있다. 이 θ에 margin을 더해 주고
scale s를 곱하면! 위 그림 Fig2 의 별표 펴진 s∗cos(θ+m) 이 구해진다.
이렇게 구한 값을 원래의 softmax의 입력으로 넣으면 additive angular margin loss가 완성고 아래와 같이 정리 할 수 있다.
L=−1Nn∑i=1loges∗cosθyies∗cosθyi+∑nj=1,j≠yi
개념
additive angular margin loss 가 동작 하는 기본 개념은 각도 차이이다.
고차원은 어려우니 저차원에서 예를 들어 보자.
입력을 아래와 같다고 하자. x=(1,2,3), W3,2=(142536)
노멀라이제이션 하면 아래와 같이 된다. (W 매트릭스는 column 축으로 normalization한다.)
x=(1√14,2√14,3√14)
W3,2=[1√144√772√144√773√144√77]
두 입력을 선형 연산 하면
$$W^{T}x= [ab]$$
가 되고 a,b는 normalization 되었으니 그 크리 |a|,|b| 는 1이다. (a,b 는 $W^Tx 의 결과를 나타내는 두 값이다. 수식을 다 쓰기 힘들어 저렇게 간단하게 표현했을 뿐이다.)
그때 W의 각 column vector (1,2,3), (4,5,6) 각각을 3차원 공간 상에서 2개 클래스의 feature의 centre 좌표로의 벡터로 본다면
입력의 feature인 x와 W의 columnd 벡터들의 내적은 각 클래스를 대표하는 feature 벡터와 입력의 feature가 이루는 각이 얼마나 작은가? 를 알아 보는 과정으로 해석 할 수 있다.
각 클래스의 대표 벡터인 W의 column 벡터들과 x 가 모두 normalization 되어있으니 그들의 magnitude는 모두 1로 같으므로
각도 (angular)의 차이만 보겠다는 뜻이다.
기하적으로 해석하면 magnitude가 모두 1이므로 각 클래스의 대표 feature 벡터 와 입력의 feature 벡터 모두 이 예에서는 3차원 공간에서 구의 표면에 위치하고 addtive angular margin loss 는 이 구의 표면 위에서 같은 클래스에 속하는 feature 벡터들이 구의 표면 상에서 서로 가까운 위치에 놓이도록 벡터간의 각도를 작게 한다는 개념이다.
Metric learning 은 데이터간의 유사도를 잘 수치화 하는 거리 함수(metric fucntion)을 학습 하는 것이다.
Metric learning loss는 입력으로 부터 추출된 feature들 간 상대적 거리를 추정하기 위한 loss로 명시적인 목표 값이 주어지고 해당 목표값 추정을 목적으로 하는 cross entropy나 regression loss와 개념이 다르다.
Detection이나 segmentation에 흔히 쓰이지는 않지만 간단하게 말하면 같은 클래스에 속한 입력간의 거리는 가깝게 만들고 하고 다른 클래스에 속한 입력간의 거리는 최대화 할때 씌인다. instance segmentation에서 같은 클래스의 서로 다른 instance를 분리 할때 유사한 개념이 사용되기도 한다.
face identification, few shot learning, recommendation 등에 사용할 수 있다.
널리 알려진 것중 이 포스트 에서 알아 볼건 triplets loss 이다.
triplets loss
Fig 1. Triplet loss의 개념
triplets loss는 Rk 에서(k는 feature의 dimension) 같은 클래스 또는 특정한 기준에서 유사한 입력 사이의 거리를 가깝게 하고 서로 다른 클래스, 유사하지 않은 입력 사이의 거리를 멀게 만드는데 목적이 있다. Fig 1. 에서 Anchor는 기준이 되는 입력이고 Negative는 입력과 다른 클래스 , Positive는 입력과 같은 클래스이다.
그림에서 알 수 있듯이 LEARNING 하고 난 후 Anchor,Positive sample사이의 거리는 가까워 졌고 Anchor, Negative sample 사이의 거리는 멀어 졌다.
입력이 이미지 일때를 기준으로 예를 들어 보자.
Fig 2. Triplet loss의 예
위 그림에서 입력을 얼굴 사진들을 xa, xp, xn 이라 했을 때 - xa, xp 는 서로 같은 사람의 얼굴, 즉 같은 클래스 - xa,xn 은 서로 다른 사람의 얼굴, 즉 다른 클래스 이다.
여기서 xp, xn을 xa 를 기준으로 같은 클래스, 다른 클래스로 구분을 했는데 이렇게 기준이 되는 입력을 anchor라고 표현하고 anchor 같은 클래스면 positive sample anchor와 다른 클래스 이면 negative sample이라 한다. (입력 x의 아래 첨자가 a,p,n인 이유가 anchor, positive, negative 의 앞 글자를 딴것이다. )
d(xi,xj) 를 Rk 에서의 xi, xj 사이의 거리라 할때 triplet loss의 목적은 아래와 같다. - d(xa,xp)는 최소화 - d(xa,xn)는 최대화
이때 단순히 최대화 하는것은 목적이 불분명하니 특정한 기준α을 도입해 같은 클래스 간의 거리보다 서로 다른 클래스간의 거리가 α 만큼 크도록 수식을 구성하면 아래 식과 같다. d(xa,xn)>d(xa,xp)+α
위 수식은 L(xa,xp,xn)=d(xa,xp)−d(xa,xn)+α 으로 다시쓸 수 있는데 d(xa,xn) 이 커져서 위 수식이 0이하가 되면 그로 부터 network가 배울 필요가 없으니 max(0,d(xa,xp)−d(xa,xn)+α) 으로 사용한다.
triplet loss를 사용할때 주의 할점
이 로스는 xa,xp,xn 의 3쌍이 필요한데 이 3개의 쌍을 어떻게 선택하느냐에 따라 학습의 안정성과 성능이 달라질 수 있다. d(xa,xp) 가 너무 작은 쌍이 dataset의 대부분을 이루고 있다면 여기서 배우는 정보량이 너무 적을수 있고 d(xa,xn)가 이미 이미 margin 역할을 하는 α보다 크면 이런 샘플에서도 학습할 정보량이 부족하다. 특히 negative sample의 선택이 중요하다고 보는 경우가 많다. negative sample에 따라 * Easy Triplets: d(xa,xn)>d(xa,xp)+alpha 인 경우 * Hard Triplets: d(xa,xn)<d(xa,xp) 인 경우 * Semi-Hard Triplets:d(xa,xp)<d(xa,xn)<d(xa,xp)+α 인 경우 로 나누기도 한다.
거리를 계산하는 함수 d(xi,xj)는 Euclidian 등 원하는 방식을 선택하면 된다.
참조
pytorch에 torch.nn.TripletMarginLoss 가 있지만 (xa,xp,xn) 샘플을 자동으로 선택해주는 기능은 없는 것으로 보인다.
pytube는 youtube stream을 다운받는 역할을 하고 requests-html은 HTML의 파싱을 쉽게 해주는 모듈이다.
예제
import http
from requests_html import HTMLSession
import pytube
from pytube.cli import on_progress
defdownload(url, id, save_dir="./downloads"):
yt = pytube.YouTube(url, on_progress_callback=on_progress) # youtube 오브젝스 생성, on_progess_callback은 video stream 의 chunk 가 다운로드 됐을때 마다 실행되는 함수. 여기서는 프로그래서 바를 그리는 용도
stream = yt.streams.filter(progressive=True, file_extension="mp4").order_by("resolution").desc().first()# progressive는 스트리밍 서비스의 종류. mp4 포멧의 비디오 파일만 필터링.
filepath = stream.download(save_dir) #다운로드.if __name__=='__main__':
s = HTMLSession()
urls = ['https://youtube.com/playlist?list=PLWo1h5t1i9PHtpcwXa04EWQri_ZZeTFGY']
total=0
i=0
save_dir = './downloads'for url in urls:
r = s.get(url) # 원하는 url에 GET request 를 보낸다.
r.html.render(sleep=0, keep_page = True, scrolldown = 10) # get 한 웹페이지를 해석하는 부분이라고 생각하면 됨
length= len(r.html.find('a#video-title'))
total+=length
for links in r.html.find('a#video-title'): #위 url 페이지에 리스팅된 제목에 해당하는 영상들의 정보를 검색
link = next(iter(links.absolute_links)) # 각 리스팅된 영상중 하나의 url을 받음print('link:{}'.format(link))
try:
download(link,i,save_dir) # 다울로드
i+=1print(fr' number of videos:{i}/{total}')
except http.client.IncompleteRead as e:
print('fail: {} \n'.format(link))
print(fr'total videos:{i}/{total}')
위 예제 코드는 내가 사용한 코드이다. 각 부분에 주석을 달아 놓았으니 편하게 읽어 보면 된다.
코드에서 r.html.find('a#video-title') 이 부분은 아래와 같은 페이지에서 리스팅된 제목에 해당하는 영상의 정보를 들고 가지고 잇는 html 요소를 찾아서 리턴해 주는 역할을 한다. 즉 '푸드얍 15초 공식 광고' 와 같은 제목에 해당하는 영상의 정보를 리턴해주는 메서드.
최근 pytorch version을 1.4에서 1.7로 업그래이드 하면서 개발 환경이 삐그덕 거리기 시작해
발생하는 문제와 해결 했던 방법을 정리 하고자 한다.
기존 개발 환경:
docker + ngc(apex, torch.1.4, cuda 10.1) + single node -multigpu
new 개발 환경:
docker + ngc(torch.distributed, torch.1.7, cuda 10.1) + single node - multi gpu
발생 문제:
DDP module 을 기존 apex에서 torch.nn.parallel.DistributedDataParallel로 변경 후 아래와 같이
실행 하면 전에 볼수 없었던 에러 메시지 발생
python -m torch.distributed.launch 00nproc_per_node 4 train.py
"아래가 발생 에러""Single-Process Multi-GPU is not the recommended mode for "
/opt/conda/lib/python3.6/site-packages/torch/nn/parallel/distributed.py:448:
UserWarning: Single-Process Multi-GPU is not the recommended mode for DDP.
In this mode, each DDP instance operates on multiple devices and creates multiple
module replicas within one process.
The overhead of scatter/gather and GIL contention in every forward pass can slow down
training. Please consider using one DDP instance per device or per module replica by
explicitly setting device_ids or CUDA_VISIBLE_DEVICES.
Traceback (Most recent call last):
~
~
RuntimeError: All tensors must be on devices[0]: 0
에러 발생 원인 코드:
위 에러가 발생한 순간은 아래와 같이 apex.parallel 의 ddp 모듈을 torch의 ddp 모듈로 바꾼뒤이고
#from apex.parallel import DistributedDataParallel as DDPfrom torch.nn.parallel import DistributedDAtaParallel as DDP
DDP로 모델을 감싸는 부분에서 위 에러가 발생했다.
#기존 에러 발생 코드 (torch.1.4 및 apex에서는 정상동작)
mymodel = DDP(mymodel)
해결방법:
문제를 해결 하기 위해서는 위의 model을 DDP로 감싸는 부분을 아래와 같이 바꿔 주면 된다.
이 논문에서는 coordinate transform 라는 문제를 제기 하고 우리에게 친숙한 convolution이 태생적인 문제(= translation invariant)로
인해 coordinate transform문제에 굉장히 취약 하다는 것을 보였고 CoordConv라는 간단한 개념을 도임해 이를 해결할 수 있다고 주장한다.
그럼 coordinate transform 이 뭘까 ?
이 논문은 우리가 암묵적으로 convolution을 이용해 굉장히 많이 풀고 있는 문제의 가장 기초적인 두 가지 문제를 convolution이 놀랍도록 못 푼다는 발견에서 시작 한다.
위에서 말한 두 가지 문제는 coordinate classification, coodinate regressiong 이다. 말이 어려워 보일 수 있는데 위 그림 Figrue 1의 가장 위쪽 그림을 보면 이해가 정말 쉽다.
coordinate classification문제는 네트워크의 입력으로 (x,y) 좌표(cartesian coordinate)을 넣고 출력으로 해당 (x,y)좌표에 해당하는 pixel만 1의 값을 갖는( 예를 들어 1이라고 했는데 사실 이 숫자는 background와 구분되기만 하면 된다. class 라고 보면 된다.)이미지를 출력하는 문제이다.
즉 좌표가 주어졌을때 해당 좌표에 흰색 점을 하나 찍은 이미지를 그려주는 문제가 coordinate classification이다.
다음으로 coordinate regression 문제는 coordinate classification 문제와 입력과 출력이 바뀐 문제이다.
즉입력으로 특정한 한 픽셀만 1의 값을 갖는 이미지를 입력으로 넣었을 때 해당 픽셀의 (x,y)좌표(cartesian coordiante)를 출력으로 내놓는 문제이다. (object detection 이 익순한 분들은 이 문제가 object detection의 bbox regreesion 문제나 key point estimation 문제와 같다는 걸 바로 알수 있을 거다.)
이 두 문제의 정의를 이해 했으면 아래 내용은 정말 간단히 쉽게 이해 할 수 있다.
(참고로 본래 논문에서는 GAN 의 mode collapse 문제도 다루고 figure 1의 가장 아래 그림도 이에 대한 내용인데 이 문제에 대한 설명은 이 포스팅에서는 최소화 하겠다.)
Convolution은 뭘 못하는가?
Figure 2. Data set 정의
Convolution이 뭘 못하는지 보기 전에 convolution의 무능을 입증하기 위해 어떤 데이터 셋을 사용 했는지 보자.
Figure 2의 (a)에는 총 9 개의 샘플 이미지가 있다. 각 이미지는 64 x 64 크기이고 단 1 픽셀을 제외한 모든 픽셀의 값이 0이다. 즉 64 x 64 사이즈의 이미지에서 오직 1픽셀만 target인 one-hot encoding 된 이미지라고 볼 수 있다.
(구태여 부연 설명을 하자면 왜 one-hot encoding이냐면 64x64 = 4096으로 vector로 표시 할수 있다.
4096 length의 vector에서 오직 한 element만 값이 1 이라고 생각해 보면 이게 one-hot encoding 이라는 걸 알수 있다. )
(a)를 이해 했으면 (b)를 보자. Figure 2. (b)의 윗줄에 있는 두 그림은 (a)처럼 one-hot encoding된 이미지를 train set, test set으로 나누고 각 데이터 셋에 해당하는 이미지를 모두 합해 하나의 이미지에 나타낸 것이다. 말이 이해가 잘 안될 수 있으니 아래 그림 Figure 3을 보자.
Figure 3. one-hot encoding 이미지의 합
Figure 3에서 화살표 왼쪽에 있는 그림을 3x3사이즈의 one-hot encoding 이미지라 하자.
이 이미지들을 다 더하고 나면 화살표 오른쪽의 결합 이미지가 된다.
Figure 3의 화살표 왼쪽에 있는 이미지가 Figure 2의 (a)에 표시된 sample이미지에 대응 되고 화살표 오른 쪽에 있는 이미지가 Figure 2 (b)에 있는 합 이미지 이다.
다시 Figure 2의 데이터 셋을 설명하면 논문의 저자는 train-test data set 을 두 가지 기준으로 분리했다.
train-test data set pair 1, train-test data set pair 2를 만들고 각각의 train set을 이용해 학습 하고 test set으로 테스트 했을 때 어떤 결과가 나오는지 보였다.
1. train-test data set pair 1: 1값을 가지는 pixel이 이미지의 아무 곳에나 위치 할 수 있게 하고 train과 test 셋을 uniform distribution 을 이용해 구분했다. Figure 2 (b)의 윗쪽 두 이미지가 각각 train, test data set을 하나의 이미지로 합친 그림이다.
2. train-test data set pair 2: image를 4개의 사분면으로 나누고 1,2,3 사분면에 값이 1인 pixel이 위치한 one-hot encoding 이미지는 train set으로 사용 하고 4 사분면에 pixel 값이 1인 point가 위치한 경우는 test 셋으로 사용 하는 경우이다. (이 경우 네트워크는 학습시 4사 분면에 위치한 sample을 본적이 없기 떄문에 4분면에 위치한 point에 대해 coordinate classification문제를 풀수 있을까?)
데이터 셋 설명이 장황해 졌는데 위 두 데이터 셋으로 coordinate classification 네트워크(일반 convolution 사용)를 학습해 보면 아래 Figure 4와 같은 결과가 나온다.
Figure 4의 (a) 그래프는 train-test accuracy 의 경향을 보여준다. 그래프의 좌상단을 보면 uniform○, quadrant■이라는 걸 보수 있는데
uniform ○ 은 위에 설명한 train-test data set pair 1로 학습-테스트를 진행한 결과 이고
quadrant■ 는 train-test data set pair 2로 학습-테스트를 진행한 결과 이다.
(헷갈리면 반드시 위에 가서 train-test data set pair에 대한 설명을 다시 확인하고 올것.)
uniform 한 데이터 셋을 사용한 경우 학습과 테스트시 그나마 어느정도는 비슷한 accuracy 경향성을 보이지만 (사실 경향성이라고 말하기 힘들다) quadrant 한 데이터 셋을 사용 한 경우 train에 오버 피팅되는 것을 볼수 있다. 즉 quadrant 데이터 셋의 경우 학습 시 네트워크는 1,2,3 사 분면에 target이 위치한 경우만 볼수 있고 테스트시에 처음 4사분면에 잇는 target을 보면 정신을 못 차린다는 것이다.
다음으로 Figure 4 (b)는 uniform 하게 train-test data set을 나누고 학습 했을때 학습시간에 따라 test accuracy를 도식화 한 그래프 인데 그 값이 86%를 넘어가지 않는다.
즉 여기서 우리가 알 수 있는건 (저자가 말하고자하는 바는) 기존의 convolution은 이 단순한 문제(coordinate classification, coordinate regression)를 정말 심각할 정도로 못푼다는 것이다.
CoordConv:
바로 위에서 convolution이 뭘 못하는 지를 봤다. 이번엔 그 문제를 저자가 어떤 아이디어로 해결하는지를 보자. 정말 단순하고 간단하다.
Figure 5. (좌) 일반 convolution, (우) CoordConv: 제안하는 방식
Figure 5의 왼쪽엔 기존의 convolution이 나와있다. 그리고 오른쪽엔 논문에서 제안하는 CoordConv이다.
CoordConv의 아이디어는 Convolution이 translation invariant한 특성이 있으니 위치에 대한 정보를 알려줘서 신경 쓰게 하는 것이다. (solo 논문에서는 이걸 "coordinate aware" 라고 표현했다.)
이를 위해서 coordconv의 입력 tensor 크기에 대응 하는 좌표를 (-1,1)로 normalize해서 concat 하는 것이다. 이것도 말로 하면 어려운데 코드를 보면 직관적이다.
x_range = torch.linspace(-1,1, inputTensor[1].shape[-1]) # inputTensor의 0번재 dimension은 batch
y_range = torch.linspace(-1,1, inputTensor[1].shape[-2]) # inputTensor의 0번재 dimension은 batch
y,x = torch.meshgrid(y_range, x_range)
y = y.expand([batchSize, 1,-1,-1]) # j coordinate in Figure 5
x = x.expand([batchSize, 1,-1,-1]) # i coordinate in Figure 5
normalized_coord = torch.cat([x,y],1)
new_feature = torch.cat([features_normalized_coord],1)
위 코드에서 y,x는 각각 Figure 5 오른 쪽의 i cooridnate, j coordinate에 대응 하는 것이고
new_feature는 Figure 5 의 CoordConv에서 concatenate Channels 바로 다음의 h×w×c+2 shape을 가지는 tensor에 해당한다.
결과:
Figure 6. CoordConv 학습 결과
Figure 6는 Figure 4와 같은 이미지이다. 위의 "Convolution은 뭘 못하는가?"란에서 설명한 두 데이터 셋
uniform(train-test data set pair 1), quadrant(train-test data set pair 2) 에 대해 CoordConv가 어떤 성능을 보이는 지 보자.
Figure 6의 왼쪽 아래 그림에서 보면 train accuracy와 test accuracy가 일치 하는것을 볼 수 있고 오른쪽 그래프를 보면 학습 시간이 25초만 되도 convolution과 달리 accuracy가 1까지 올라간다.
Figure 번호가 햇갈릴수 있음에도 불구하고 위 figure 7 은 원 논문의 caption을 같이 올렸다. (설명이 햇갈리시면 영문을 읽는게 더 쉬울수 있으므로..)
Figure 7의 왼쪽은 coordinate classification의 학습데이터(가장 왼쪽 줄)와 테스트 inference결과(붉은 색 박스 안쪽)를 보여준다. coordinate classification는 앞에서 설명 한것 처럼 (x,y)를 입력 했을때 이미지에 해당하는 pixel에 색을 칠하는 문제이다. 붉은 박스의 가운데 그림이 convolution으로 inference한 결과를 시각화 한건데 제일 윗줄에 있는 GT 이미지에 4사분면이 가득 차 있는 것과 달리 4사분면이 거의 비어있는 것을 볼 수 있다.
반면 CoordConv는 4사분면에 있는 점들을 잘 그리고 있다.
Figure 7의 오른쪽은 coordinate regression을 학습한 결과를 시각화 한것이다. (coordinate regression은 one-hot image를 입력으로 넣고 target pixel의 (x,y)를 출력하는 문제이다. 시각화 한건 출력인 (x,y)를 다시 이미지에 표시한 것이다.)
파란색 박스 안쪽을 보면 convolution은 train데이터에 대해서도 test데이터에 대해서도 추정한 결과가 울퉁불퉁 한 반면, CoordConv는 결과가 GT와 거의 일치 한다.
정리:
Convolution이 어떤 취약점을 가지고 있는지 비교적 간단한 실험을 통해 알아 보고 이 문제를 해결하기 위한 방법 정리해봤다.
내 입장에서 CoordConv가 효과를 발휘 할 수 있는 문제는 어떤 식으로든 image로 부터 좌표를 추측하는 문제 즉 object detection일거 같다. 논문의 결과에도 object detection에서 (mnist data셋 기준) 상당한 성능 향상을 보았다고 리포팅했다.
CoordConv를 사용해도 효과가 없는 문제는 object의 위치와 관련 없는 문제 즉 classification문제 이다.
위에서 언급은 안했지만 논문을 보면 저자는 mode collapse에 대한 이야기도 하지만 이 포스트에는 정리하지 않았다. 당장의 내 관심사와는 좀 거리가 있고 내 이해가 부족하기도 해서이다.
이 논문은 e2e로 학습도 가능 하고 instance를 구분 하는 방식이 매우 흥미 롭다.
SOLO의 접근 방식:
SOLO에서 해결하고자 하는 건 instance segmentation 이다.
이미지 상에 존재하는 여러 물체를 각각 구분해 mask를 생성하는 문제이다.
이를 위해 SOLO에서는 object center와 size정보를 이용한다.
bbox 예측이나 post processing을 통한 instance pixel grouping없이 개별 object를 위 언급한 object center와 size를 이용해 정의한 center region와 해당 region에 대응 하는 mask로 직접 instance mask를 생성한다.
간단히 기존 instance segmentation 네트워크의 전략을 살펴 보면 크게 top-down, bottom-up 방식으로 나눌 수 있다.
top-down 방식: bbox 찾고 해당 bbox 안에 있는 object mask를 생성. 이 방식에서 instance의 구분은 bbox거의 전적으로 의존하게 된다. 대표적인 모델은 Mask-RCNN, PANet(mask-rcnn에서 feature representation을 강화한 방식, Mask-scroing rcnn(mask prediction의 품질을 평가하기 위한 mask-iou branch를 도입)
bottom up 방식: 이 방식의 네트워크 들은 대부분 각각의 object를 구분하기 위해 bbox를 사용하는 대신 각 object를 구분할 수 있는 임의의 latent space에서 각 object를 나타내는 pixel embedding(의 형태는 다양 할 수 있다.)을 학습하고 post processing을 통해 grouping 한다. 대표적인 모델은 1. SGN: instance segmentation을 단계적인 sub-grouping문제로 정의. break point 라는 개념을 도입해 각 instance의 경계에 있는 point를 찾고 이 point를 line segment로 line segment를 instance를 grouping해 instance를 구성한다. 2. SSAP(single shot instance segmentation with affinity pyramid): pixel이 같은 인스턴스에 속하는 지를 pixel pair affinity라는 확률 값을 계산 하는 문제로 정의
SOLO는 bbox를 찾지도 pixel embedding을 학습해 후처리로 그룹핑 하지도 않고 mask 를 바로 생성하기 떄문에
Direct mask prediction 이라고 할 수 있다.
SOLO Architecture:
Fig 1. Solo framework. grid size=5 일 때
Fig 1. 은 매우 직관적으로 solo의 framework을 이해 할 수 있다.
전체 흐름을 간단히 보면 입력 이미지를 SxS grid로 나타내고 어떤 object의 center가 특정 grid cell에 위치하면
그 cell이 sementic category와 instance mask를 예측하는 책임을 진다.
Sementic Category:
sementic category는 object의 class를 예측하는 branch이다.
Object class 가 c개 있다면 category branch는 S×S×C 형태의 tensor를 생성한다. 이때 grid cell (i,j)에 있는 길이 c의 vector는 해당 cell에 object center가 존재하는 객채가 어떤 class에 속할지 에 대한 확률값 벡터이다.
Instance mask:
Instance mask head의 output shape은 H×W×S2 이다.
채널이 S2 인 이유는 grid cell (i,j) 각각에 대응 하는 채널이 하나씩 있기 때문이다.
즉 Intance mask의 각 채널은 category branch의 grid cell (i,j)와 1:1 매핑 되는 관계이다.
예를 들어 임의의 객체 A의 center가 grid cell (i,j)에 위치 한다면 이 객체의 segmentation mask는
maskchannel=i×S+j intance mask 에 생성되게 끔 네트워크를 학습한다.
Fig 1.의 input image와 category branch 를 보면 왼쪽 얼룩말의 센터는 grid cell에서 붉은 색(i1,j1)으로, 오른쪽 얼룩 말의 센터는 grid cell에서 파란색(i2,j2)으로 표시 된다. 그리고 이 두 얼룩말의 마스크는 각 grid cell에 대응 하는 intance mask channel i1×S+j1, i2×S+j2에 각각 생성되는 식이다.
이렇게 grid cell 위치와 instance mask 채널이 서로 연관되어 있기 때문에 SOLO는 "coordinate aware" convolution을 사용 했다고 한다.(기존 convolution은 translation invarian한 특성을 가지고 있기 떄문에 이와는 구분된다.)
그리고 이를 위해 CoordConv라는 convolution을 사용 했다.
CoordConv는 instance mask branch의 입력과 같은 spatial size를 갖는 H×W\tmes2 크기의 텐서에 coordinate을 [-1,1]로 normalize하고 backbone의 output에 concat해서 instance mask branch에서 사용 한다.
Fig 2의 Mask branch에서 input channel이 (256+2)인 이유가 바로 이 coordinate 정보를 concat했기 때문 이다.
아래 코드를 보면 쉽게 이해가 된다.
코드입력
Fig 2. SOLO category and Mask branch
FPN:
SOLO는 feature pyramid layer(FPN)의 output이 각 category branch와 mask branch의 입력으로 사용되어 서로 다른 크기의 object를 찾는 효율을 높였다.
학습:
GT 생성:
intance mask를 category classification grid cell위치에 대응 하는 instance mask channel에 binary mask 형태로 생성한다. 따라서 학습시 instance mask를 이에 대응 하는 형태로 만들어야 한다.
앞서 object center가 (i, j) grid cell에 위치한다고 할때 해당 cell 이 object의 class와 mask생성을 담당한다고 했다. 이때, object size에 따라 여러 cell이 한 object의 class와 mask생성을 담당할 수도 있다. object center 좌표는 object mask gt 의 centre of mass로 정의하고 object 크기를 고려해 center sampling을 하기 위해 center region은 (Cx,Cy,ϵW,ϵH)ϵ=0.2 로 정의한다.
이렇게 center region을 정하고 나면 category grid cell 상에 아래와 같이 center region이 형성될 수 있는데 이때 각 cell 위치에 해당하는 instance mask channel의 binary mask가 똑같이 들어간다.
Fig 3은 이해를 돕기 위해 그린 그림이다. 붉은 색영역은 임의의 object에 대한 center region 이고 이에 대응 하는 mask gt가 intance mask gt에 어떻게 저장되는지 보여 준다.
Fig 3. center region 과 instance mask gt 예시
LOSS:
totalloss=Lcategory+\lambdaLmasks
Category classification($L_{category}):
solo는 category classification을 위해 focal loss를 사용 했다. (굳이 식을 설명하지 않아도 될정도로 많이 사용되니 식은 생략한다.)
inference 시 category score threshold는 0.1을 사용해 낮은 score를 필터링 하고 score상위 500개에 대응되는 mask에 NMS를 적용한다.
최종 score를 계산하기 위해선 maskness를 category score에 곱해 주는데 maskness란 1Nf∑pi로 표현되고 pi는 prediction mask의 pixel value 다.
(mask ness 를 곱해주는 의미는 maskness점수가 높다는게 곧 해당 object의 형태를 잘 찾았다는 것일 태니 그걸 최종 score에 반영하는 것 같다. )
결과:
Fig 4. COCO 데이터셋에 대한 solo 학습 결과
Fig 4.에서 볼 수 있듯이 SOLO는 Mask R-CNN과 비슷 하거나 더 좋은 결과를 보여 준다. one stage instance segmenation이 two stage보다 좋아 질 수 있다는 충분한 가능성을 보여주는 예시 인거 같다.
가장 좋은 성능을 보인것은 Resnet 101 backbone+ deformable convolution+ FPN을 사용 한 모델이다.
Fig 5. SOLO behavior 설명
Fig 5에서는 SOLO가 어떻게 동작 하는지를 볼 수 있는데 아랫 줄의 보라색은 category branch 의 grid 가 12 x12일때
대응 되는 instance mask branch의 각 채널이 어떤 prediction결과를 가지는 지 보여준다.
instance mask branch output의 각 채널은 하나의 object에 대응 하는 mask를 생성하는 것을 볼 수 있는데 이 mask는 해당 채널과 대응 하는 category branch의 grid cell에 center가 위치하는 객채의 마스크 이다.
객체의 크기에 따라 center region 이 여러 cell을 포함 할 수 있기때문에 대응 되는 intance mask channel도 여러개 일수 있어서 한 object의 mask가 여러개 생성되는 모습을 볼 수 있는데 NMS를 이용해 같은 객체의 mask를 하나로 합친다.
Fig 6. FPN grid size의 영향성
Fig 6은 category branch의 grid size에 따른 AP 결과를 보여 준다. grid number 12,24,36은 단일 grid size를 사용 했을 경우를 말하고 Pyramid는 FPN을 사용해 여러 grid size를 사용해 결과를 추정 했을때를 말한다.
단일 size이 grid를 사용할 경우 grid size가 클수록 AP가 높게 나왔고 FPN을 사용해 여러 grid size를 고려 하는게 가장 높은 결과를 모여준다. FPN의 경우 다양한 object 크기를 고려 할 수 있으니 당연한 결과로 생각된다.
Fig 7. CoordConv 영향성
Fig 7은 coordinate aware convolution 이 결과에 어떤 영향을 미치는지에 대한 테스트 이다.
Coordconv 를 사용 하지 않을 경우 Fig 7 테이블의 가장 윗줄의 AP =32.2가 coorconv를 사용했을 때보다 최소 3.6point가 낮은 결과를 보여 준다. 비슷 하게 coordconv를 2회 이상 사용하는 것은 성능에 영향을 거의 미치지 않는 것을 볼 수 있기 때문에 논문에서는 2회만 사용 했다.
논문에서는 좀더 많은 ablation experiment를 진행했지만 이정도만 정리해도 충분할거 같다.