
deeplearning 기반 tracking 로직의 발전 과정을 보면 object detection 모델의 발전사와 방향이 거의 일치 한다.
오늘은 FairMOT 라는 one stage 기반 tracking 로직을 정리 해 본다.
논문:
FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
기존 모델의 단점:
two-stage model의 단점:
기존 모델은 Re-ID 를 위한 data asoociation feature 와 object detection 을 위해 서로 다른 모델을 사용했다.
즉 two stage 모델을 사용했다. 즉 , obejct detection -> crop object bounding box -> association vector extractor 와 같은 순으로 두개의 서로 다른 모델이 사용된다. ([tracking] deep learning 기반 트래킹 정리] 의 Fig 3. 을 참조하자.)
이런 two-step 기반 tracking model 들은 추적해야할 객체가 많을 경우 실시간 성능을 발휘 하기 어렵다. obejct detection 모델과 feature를 공유 하지 않으므로 모든 image 내의 모든 object에 대해 re-ID 를 위한 feature 추출을 모두 새로 해야 하기 때문이다.
기존 one stage tracking model의 단점:
1. anchor 공유의 문제: anchor 기반 detection model에서 한 anchor를 detection 과 re-ID feature 추출을 위해 공유 하면 모델은 detection 성능에 overfitting 될수 있다. 또한 하나의 anchor 가 여러 객체의 re-ID feature 추출에 공유 될수도 있고 여러 anchor 가 한 object의 re-ID feature 추출을 담당 할 수도 있다. Fig 1. 은 anchor 공유의 문제점을 시각화 한것이다. (b)는 한 anchor가 두 객체 detection을 담당하는 경우, (c)는 여러 anchor가 하나의 객체 detection에 씌이는 문제를 나타내나.
2. feature 공유의 문제: detection 과 re-ID feature는 서로 다른 특징을 같는다. detection 은 같은 클래스에 속한 object 들의 공통된 feature 를 찾는게 유리하고 re-ID 를 위해선 동일 클래스에 속한 instance를 구분할 수 있는 feature 를 찾아야 한다.
3. feature dimension: re-ID 에 사용되는 feature dimension은 보통 512 또는 1024 로 object detection 에 쓰이는 것보다 high dimension 이다. detection 과 re-ID의 이러한 dimension 차이는 두 테스크의 성능 모두에 해롭다.

FairMOT
FairMOT는 Fig 2. 에서 와같이 detection과 re-ID feature를 하나의 모델에서 추론하는 방식이다.
FairMOT 는 MOT(multiple object tracking) 자체는 연속된 프레임간 one-to-one object mathing 문제를 푸는 것이기 때문에 re-ID 문제와는 다르다고 선을 긋는다. 그렇게 때문에 re-ID에서 필요로 하는 high dimensional feature보다 low dimensional feature 학습 함으로써 detection task와 re-ID task 간의 균형을 맞추고 인퍼런스 속도를 향상 할 수 있었다.
encoder-decoder
backbone: resnet-34 + modified DLA(deep layer aggregation).
decoder의 upsampling 시에는 deformable convolution을 사용한다. output stride 는 4 이다.
FairMoT는 위 '기존 one stage tracking model의 단점' 1. 에서 언급한 anchor 기반 모델의 단점을 극복하기 위해 anchor free detector 인 centerNet을 사용 했다. 이렇게 함으로서 Fig 1. (d) 와 같이 object center에 re-id feature 를 추출 함으로서 two stage에서 문제가 되었던 bbox내의 배경, anchor 기반 detector 에서 한 anchor 가 여러 object를 담당하거나 한 object를 담당하는 여러 anchor가 있는 문제 등을 해결 했다.
centernet의 구조 자체에 대한 설명은 생략한다.
re-ID branch
Re-ID 헤드는 $E \in R^{128xhxw}$ 의 맵을 출력한다. $E$의 크기 인 $h x w$ 는 model input의 1/4 사이즈 이다.
$E_{(x,y)} \in R^{128}$ 이고 x,y 좌표는 object의 center 좌표로 detection head의 heatmap으로 부터 구할수 있다.
학습 단계에서 추출한 re-ID feature $E$는 fully connected layer를 이용해 class distribution $P={ p(k) , k \in (1,k)}$ 를 추론하는데 씌인다.
이렇게 추출된 $p(k)$는 $L(k)$와 cross entropy 연산에 씌인다. 아래는 re-ID의 최종 cost function 이다.
$$L_{identity} = -\sum^{N}_{i=1}\sum^{k}_{k=1}L^{i}(k)\log{p(k)} $$
re-ID를 feature를 학습 하는 전략은 다음과 같다.
data set에 존재하는 동일 object instance는 모두 같은 class로 분류 하고 학습시 classification 처럼 re-ID head의 output을 이용해 학습한다.
그럼 서로 다른 object instance 의 re-ID feature $E \in R^{128}$은 128차원 공간에서 서로 멀리 떨어져 있고 동일 object instance를 나타내는 re-ID feature $E \in R^{128}$은 서로 가까이 위치하도록 embedding이 학습 될 것이다.
detection과 re-ID head를 모두 고려 한 FairMOT의 최종 loss는 아래와 같다.
$$L_{total}=\frac{1}{2} (\frac{1}{e^{w_{1}}} L_{detetion} + \frac{1}{e^{w_{2}}} L_{identity} +w_{1} + w_{2}) $$
$w_{1}, w_{2}$ 는 학습 가능한 파라미터로 detection과 re-ID feature 학습 간의 균형을 맞추는 역할을 한다.
online association
추론 단계에서는 $E \in R^{128}$ 을 입력으로 classification을 위해 사용 하던 fully connected layer를 제거 하고 $E \in R^{128}$ 자체를 appearance vector(re-ID feature)로 사용해 연속된 프레임 상의 object들이 서로 같은 object인지 판단 하는 data association을 위한 feature 로 사용한다.
그림으로 보자면 아래 Fig 3. 의 Re-ID Embedding에서 object center 에 해당 하는 위치에서 뽑아낸 vector들이 $E \in R^{128}$에 해당한다.
tracking
아래 Fig 4.는 FairMoT의 tracking flow diagram 이다. 큰 흐름은 DeepSort와 같고 data association에 사용하는 feature를 생성하는 방식에 차이가 있을 뿐이다. 다만 이 작은 차이가 성능의 차이를 만들어 냈다. Fig 4.의 붉은 점선으로 나타낸 원 부분이 DeepSORT 와 차이가 나는 부분이다. 다이어그램이 정확히 이해가 되지 않으면 '[tracking] deep learning 기반 트래킹 정리' 포스트를 참조하자.
성능
논문은 다양한 관점에서 다른 접근방식들과 성능을 비교 했다. 양이 방대해 여기에 다 정리하진 않을 것이다. 자세한건 논문을 참조 바란다.
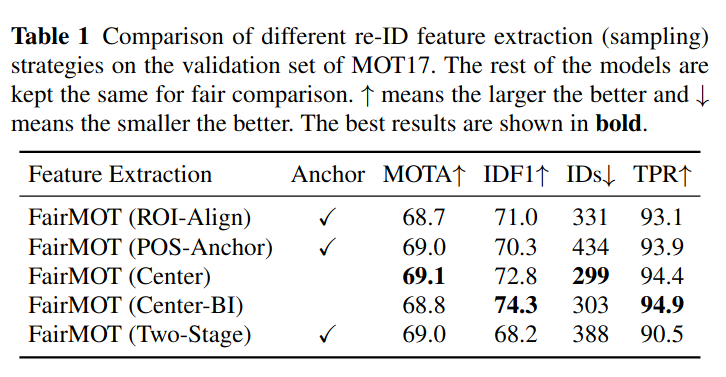
아래 Table 1은 re-ID 를 위한 feature를 sampling 하는 방법에 따른 성능을 정리한 것이다.
첫번 째 줄은 ROI-Align 방식(Track R-CNN 에서 사용)으로 detection proposal 에서 ROI-Align을 이용해 re-id feature를 추출한다. feature추출위 치가 object의 center 에서 벗어나는게 많다. 두번째 POS-Ancho로 JDE에서 사용된 방식으로 anchor 기반의 방식이다 역시 object center 에서 벗어난 위치에서 feature 가 추출될 확률이 높다. 세번째 줄의 Center는 FairMot 에서 사용한 object center 위치에서 feature 를 추출하는 방식, Center-BI는 object center를 더 정확히 추출하기 위해 Re-ID embedding feature map 을 bilinear 로 스케일을 키워서 sample 을 추출한 것이다. 마지막 줄은 bbox를 이용해 입력 영상에서 object 를 crop하고 이를 별도의 classifier를 이용해 feature를 추출한 방식이다. 보다 시피 Center, Center-BI 의 성능이 가장 좋았다.
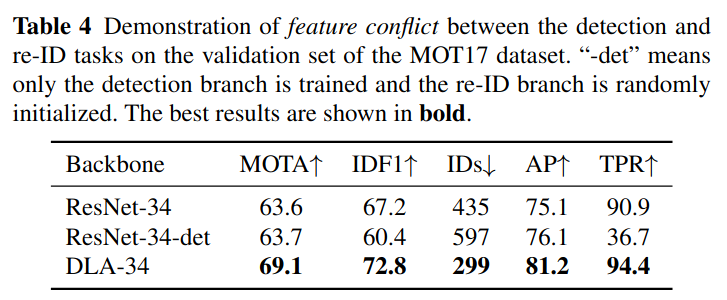
backbone 구조별 성능 차이
data association 에 사용된 정보의 조합별 성능 차이

이밖에도 자다양한 비교 결과가 논문에 자세히 나와 있으니 한번쯤 읽어 보길 바란다.
-끝-
'Tracking' 카테고리의 다른 글
| [tracking] deep learning 기반 트래킹 정리 (0) | 2023.01.05 |
|---|




