nvidia docker runtime 설치를 위해 GPG 키 추가 후 apt update 를 하니 다음과 같은 에러가 발생했다.
E: Conflicting values set for option Signed-By regarding source https://nvidia.github.io/libnvidia-container/stable/ubuntu18.04/amd64/ /: /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg !=
E: The list of sources could not be read.
기존 모델은 Re-ID 를 위한 data asoociation feature 와 object detection 을 위해 서로 다른 모델을 사용했다. 즉 two stage 모델을 사용했다. 즉 , obejct detection -> crop object bounding box -> association vector extractor 와 같은 순으로 두개의 서로 다른 모델이 사용된다. ([tracking] deep learning 기반 트래킹 정리] 의 Fig 3. 을 참조하자.) 이런 two-step 기반 tracking model 들은 추적해야할 객체가 많을 경우 실시간 성능을 발휘 하기 어렵다. obejct detection 모델과 feature를 공유 하지 않으므로 모든 image 내의 모든 object에 대해 re-ID 를 위한 feature 추출을 모두 새로 해야 하기 때문이다.
기존 one stage tracking model의 단점:
1. anchor 공유의 문제: anchor 기반 detection model에서 한 anchor를 detection 과 re-ID feature 추출을 위해 공유 하면 모델은 detection 성능에 overfitting 될수 있다. 또한 하나의 anchor 가 여러 객체의 re-ID feature 추출에 공유 될수도 있고 여러 anchor 가 한 object의 re-ID feature 추출을 담당 할 수도 있다. Fig 1. 은 anchor 공유의 문제점을 시각화 한것이다. (b)는 한 anchor가 두 객체 detection을 담당하는 경우, (c)는 여러 anchor가 하나의 객체 detection에 씌이는 문제를 나타내나.
2. feature 공유의 문제: detection 과 re-ID feature는 서로 다른 특징을 같는다. detection 은 같은 클래스에 속한 object 들의 공통된 feature 를 찾는게 유리하고 re-ID 를 위해선 동일 클래스에 속한 instance를 구분할 수 있는 feature 를 찾아야 한다.
3. feature dimension: re-ID 에 사용되는 feature dimension은 보통 512 또는 1024 로 object detection 에 쓰이는 것보다 high dimension 이다. detection 과 re-ID의 이러한 dimension 차이는 두 테스크의 성능 모두에 해롭다.
Fig 1. anchor 기반 detector의 문제점
FairMOT
Fig 2. FairMoT 구조
FairMOT는 Fig 2. 에서 와같이 detection과 re-ID feature를 하나의 모델에서 추론하는 방식이다.
FairMOT 는 MOT(multiple object tracking) 자체는 연속된 프레임간 one-to-one object mathing 문제를 푸는 것이기 때문에 re-ID 문제와는 다르다고 선을 긋는다. 그렇게 때문에 re-ID에서 필요로 하는 high dimensional feature보다 low dimensional feature 학습 함으로써 detection task와 re-ID task 간의 균형을 맞추고 인퍼런스 속도를 향상 할 수 있었다.
encoder-decoder
backbone: resnet-34 + modified DLA(deep layer aggregation). decoder의 upsampling 시에는 deformable convolution을 사용한다. output stride 는 4 이다. FairMoT는 위 '기존 one stage tracking model의 단점' 1. 에서 언급한 anchor 기반 모델의 단점을 극복하기 위해 anchor free detector 인 centerNet을 사용 했다. 이렇게 함으로서 Fig 1. (d) 와 같이 object center에 re-id feature 를 추출 함으로서 two stage에서 문제가 되었던 bbox내의 배경, anchor 기반 detector 에서 한 anchor 가 여러 object를 담당하거나 한 object를 담당하는 여러 anchor가 있는 문제 등을 해결 했다. centernet의 구조 자체에 대한 설명은 생략한다.
re-ID branch
Re-ID 헤드는 $E \in R^{128xhxw}$ 의 맵을 출력한다. $E$의 크기 인 $h x w$ 는 model input의 1/4 사이즈 이다. $E_{(x,y)} \in R^{128}$ 이고 x,y 좌표는 object의 center 좌표로 detection head의 heatmap으로 부터 구할수 있다. 학습 단계에서 추출한 re-ID feature $E$는 fully connected layer를 이용해 class distribution $P={ p(k) , k \in (1,k)}$ 를 추론하는데 씌인다. 이렇게 추출된 $p(k)$는 $L(k)$와 cross entropy 연산에 씌인다. 아래는 re-ID의 최종 cost function 이다. $$L_{identity} = -\sum^{N}_{i=1}\sum^{k}_{k=1}L^{i}(k)\log{p(k)} $$
re-ID를 feature를 학습 하는 전략은 다음과 같다. data set에 존재하는 동일 object instance는 모두 같은 class로 분류 하고 학습시 classification 처럼 re-ID head의 output을 이용해 학습한다. 그럼 서로 다른 object instance 의 re-ID feature $E \in R^{128}$은 128차원 공간에서 서로 멀리 떨어져 있고 동일 object instance를 나타내는 re-ID feature $E \in R^{128}$은 서로 가까이 위치하도록 embedding이 학습 될 것이다.
detection과 re-ID head를 모두 고려 한 FairMOT의 최종 loss는 아래와 같다. $$L_{total}=\frac{1}{2} (\frac{1}{e^{w_{1}}} L_{detetion} + \frac{1}{e^{w_{2}}} L_{identity} +w_{1} + w_{2}) $$ $w_{1}, w_{2}$ 는 학습 가능한 파라미터로 detection과 re-ID feature 학습 간의 균형을 맞추는 역할을 한다.
online association
추론 단계에서는 $E \in R^{128}$ 을 입력으로 classification을 위해 사용 하던 fully connected layer를 제거 하고 $E \in R^{128}$ 자체를 appearance vector(re-ID feature)로 사용해 연속된 프레임 상의 object들이 서로 같은 object인지 판단 하는 data association을 위한 feature 로 사용한다. 그림으로 보자면 아래 Fig 3. 의 Re-ID Embedding에서 object center 에 해당 하는 위치에서 뽑아낸 vector들이 $E \in R^{128}$에 해당한다.
Fig 3. Re-ID feature
tracking
아래 Fig 4.는 FairMoT의 tracking flow diagram 이다. 큰 흐름은 DeepSort와 같고 data association에 사용하는 feature를 생성하는 방식에 차이가 있을 뿐이다. 다만 이 작은 차이가 성능의 차이를 만들어 냈다. Fig 4.의 붉은 점선으로 나타낸 원 부분이 DeepSORT 와 차이가 나는 부분이다. 다이어그램이 정확히 이해가 되지 않으면 '[tracking] deep learning 기반 트래킹 정리' 포스트를 참조하자.
Fig 4. FairMoT tracking flow diagram
성능
논문은 다양한 관점에서 다른 접근방식들과 성능을 비교 했다. 양이 방대해 여기에 다 정리하진 않을 것이다. 자세한건 논문을 참조 바란다.
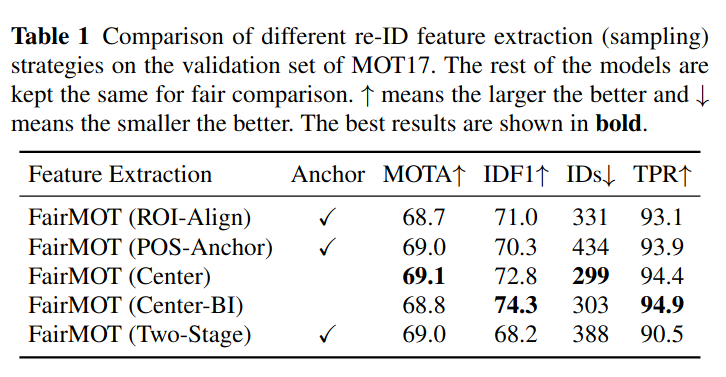
아래 Table 1은 re-ID 를 위한 feature를 sampling 하는 방법에 따른 성능을 정리한 것이다.
첫번 째 줄은 ROI-Align 방식(Track R-CNN 에서 사용)으로 detection proposal 에서 ROI-Align을 이용해 re-id feature를 추출한다. feature추출위 치가 object의 center 에서 벗어나는게 많다. 두번째 POS-Ancho로 JDE에서 사용된 방식으로 anchor 기반의 방식이다 역시 object center 에서 벗어난 위치에서 feature 가 추출될 확률이 높다. 세번째 줄의 Center는 FairMot 에서 사용한 object center 위치에서 feature 를 추출하는 방식, Center-BI는 object center를 더 정확히 추출하기 위해 Re-ID embedding feature map 을 bilinear 로 스케일을 키워서 sample 을 추출한 것이다. 마지막 줄은 bbox를 이용해 입력 영상에서 object 를 crop하고 이를 별도의 classifier를 이용해 feature를 추출한 방식이다. 보다 시피 Center, Center-BI 의 성능이 가장 좋았다.
이 포스팅에서 소개할 Multiple object tracking 패러다임은 tracking-by-detection으로 detection -> tracking 2단계로 이루어 진다. 당연하게도 detector의 성능이 좋아 지면 tracking도 더 잘될 확률이 높아진다.
트래킹도 내부적으로 motion estimation, data association, update 로 이루어져 있다.
motion estimation은 이전 프레임들에서 발견된 object bbox 들이 현재 프레임에서 어디에 위치 할 지 나이브하게 예측 하는 단계라고 보면 되고(베이지안적 시각으로 바라보면 prior distribution p(x) 에 해당), data associtaion은 연속된 프레임에서 bbox 가 서로 같은 object의 bbox 인지 best match를 찾는 과정이다(이 과정에서 best match를 찾는 것은 likelihood=p(z|x)에 해당한다. ). best match를 찾으면 motion estimation 의 output을 현재 프레임에서 찾은 bbox 정보를 이용해 update 한다.
트래킹 로직을 공부 할때 서로 다른 로직의 motion estimation 방식이 어떻게 다른지, data association을 위해 어떤 정보를 사용하는지 association에 사용하는 정보를 어떻게 구하는지 차이점을 위주로 파악 하면 이해하는데 도움이 된다.
SORT
sort 는 simple online realtime tracking 의 약자로 실시간 트래킹이 가능한 대표적인 접근 방식이다. SORT 를 이해해 두면 아래 소개할 다른 로직들을 이해하는데 큰 도움이 되는 baseline 격이다.
SORT는 detector로 Faster Region CNN (FrRCNN) detection framework을 사용하고 motion estimation을 위해 kalman filter를 사용하고 data association을 위한 정보로 현 프레임에서 detector 가 구한 BBox와 tracking 된 object bbox 사이의 IOU 를 사용한다.
Fig 1. IOU
서로 다른 프레임 사이에서 object 들간의 best match 를 찾기 위해 IOU 값을 metric으로 hungarian algorithm을 이용해 best match 를 찾는다. (kalman filter와 hungarian algorithm은 많은 트래킹 로직에서 사용되니 공부해 두면 다른 tracking 로직을 이해하는데 도움이 된다. hungarian algorithm은 많은 사람들이 잘 정리 해놔서 굳이 정리하지 않는다. )
kalman filter에서 각 object 의 state은 [ x,y, s, r, $\dot{x}$, $\dot{y}$, $\dot{s}$ ] 이다.
x, y는 object의 center position 이고 s는 scale r은 aspect ratio, $\dot{x}$, $\dot{y}$, $\dot{s}$ 는 x,y,s 의 속도 값이다.
SORT의 플로우를 diagram으로 그리면 아래와 같다.
Fig 2. SORT flow diagram
단점: object에 occlusion 이 발생하는 경우, image frame 밖으로 나갔다가 다시 들어오는 경우(re-entering), object의 외향적 특징이 변하는 변한 경우(different view point) tracking이 잘 안된다. ID switching(동일 instance의 tracking id 값이 바뀌는 것) 바뀌는 문제의 발생빈도가 상대적으로 잦다.
DeepSORT
DeepSORT는 SORT의 단점을 보강하기 위해 data association에 사용하는 feature를 보강하고 추적한 object와 현재 프레임에서 detection한 object를 매칭 하는 방법을 강화한 버전으로 전체 플로우는 SORT와 유사하다.
주로 SORT의 단점으로 거론된 occlusion, re-entering 시 발생하는 id-switching 을 개선했다. 아래 flow diagram은 DeepSORT의 동작을 시각화 한것으로 동작방식을 잘 나타냈다. 붉은색으로 강조된 박스는 DeepSORT에서 추가된 기능에 해당 된다. (모든 붉은색 블럭이 deepsort에만 있는건 아니다. iout 매칭의 결과로 나오는 unmatched track의 경우 기존 SORT에도 있지만 DeepSORT에서는 unmatched track에 대한 추가 처리를 하기 때문에 붉은색으로 표시했다.)
Fig 3. DeepSORT flow diagram
State of object in kalman filter
DeepSORT도 트래킹을 위해 기본적으로 kalman filter prediction(=motion estimation)과 update(=measurement update)를 이용한다. 이때 kalman filter에서 object state를 아래와 같이 정의 한다. $( x,y,\gamma, h, \dot{x}, \dot{y}, \dot{\gamma}, \dot{h} )$ x,y: object center location, $\gamma$: aspect rati, $h$: object height 이고 $\dot{x}, \dot{y}, \dot{\gamma}, \dot{h}$ 는 각 변수의 속도에 해당한다.
Data association
SORT 에서 data association을 위한 정보(metric)으로 단순 iou 를 사용했던 것에 비해 DeepSORT는 총 세가지 메트릭(mahalanobis distance, appearance descriptor, iou)을 사용 하고 data association은 2단계로 이루어 진다. (Fig 3. 을 참조하면서 설명을 보자)
data association의 첫번째 단계는 cascade matching, 두번째 단계는 iou matching이다.
cascade matching은 mahalanobis distance와 appearance descriptor 두 가지 메트릭을 이용해 track과 detection사이의 matching관계를 구한다. 우선 mahalanobis distance와 appearance descriptor 에 대해 살펴 보고 이 두 가지를 이용해 cascade matching에서 어떻게 track-detection matching 쌍을 구하는지 알고리즘을 살펴 보자.
1. mahalanobis distance mahalanobis distance는 distance를 구하기 위해 분산을 고려한다. 수식은 아래와 같다. $$ d^{(1)}(i,j)=(d_{i} - y_{j})^{T} S^{-1} (d_{i} - y_{j})$$ $d_{i}$ 는 현재 프레임의 detection 결과, $y_{j}$는 kalman filter prediction의 결과, $\sum^{-1}$ 는 공문산 메트릭스의 역행렬이다.
이미 알고 있겠지만 이 수식의 의미는 분산을 고려해 $d_{i}$와 $y_{j}$ 사이의 거리를 구한다는 의미로 불확실성의 정도를 거리에 반영한다는 의미이다. 이런 mahalanobis distance 의 단점은 분산이 커질 수록 서로 멀리 떨어져 있는 $d_{i}$와 $y_{j}$도 그럴 듯 한 값으로 해석한다는 것이다. Fig 4. (A), (B) 에서 $y_{j}$ 와 $d_{i}$ 의 거리는 실제로 같다. 다만 (A)는 분산이 크고 (B)는 분산이 작다. 이런 경우 mahalanobis distance 는 (A)에서 더 작다. 분산이 크기 때문에 (A) 분포 상에서 $d_{i}$ 가 더 나타날 확률이 높기 때문이다.
Fig 4. mahalanobis distance 예시
DeepSORT 에서는 mahalanobis distance에 mask를 씌우는데 특정값($t^{(1)}$) 이하인 경우만 고려하겠다는 의미이다. 논문에서는 이 마스크를 $b^{(1)}_{(i,j)}= I[d^{(1)}_{(i,j)} \le t^{(1)}]$ 라고 표현했다.
2. appearance descriptor(=embedding)
appearance descriptor는 occlusion, re-entering 가 발생했을 object나 camera의 motion이 클때 tracking 정확도를 향상시키기 위한 목적으로 추가되었다. (이 포스팅에서 appearance descriptor 는 appearance embedding 이라는 용어와 혼용해서 사용한다. 사실 appearance embedding 이 더 일반적인 용어인거 같긴하다.)
appearance descriptor는 Fig 3.에 나온것 처럼 detector 가 찾은 object 를 crop해 appearance embedding 을 추출하기 위해 별도의 CNN 에 입력으로 넣어 구한다. 각 track 은 최근 100 frame의 appearance embedding 을 유지한다.
appearance embedding 을 이용한 거리는 내적을 이용하고 아래와 같이 구한다.
위 알고리즘은 1 부터 $A_{max}$ 까지 iteration 하면서 track-detection 쌍을 매칭한다. min_cost_matching 이라고 되어 있는건 hungarian algorithm 이라고 생각하면 된다.
iteration 을 하는 이유를 알기 위해선 $age$ 라는 변수를 설명 해야 한다.DeepSORT 에서 $age$ 는 가장 마지막으로 detection 된 프레임으로 부터 얼마나 오랫동안(몇 프레임이나) detection 과 매칭되지 않았는가 를 나타내는 변수이다. (track을 얼마나 오랫동안 유지 하느냐 인건데 occlusion, re-entering 시 ID-switching 을 예방하는데 도움이 된다.)
이 pseudo code에서 $A_{max}$ 가 $age$를 나타내는 값이다. $age$ 값이 작은 값을 가지는 track 부터 track-detection 간 매칭을 구하기 위해 사용하는데 $age$ 값이 작을 수록 kalman filter prediction 의 uncertainty(분산) 이 작으므로 이런 track 들에 detection 과 매칭될 기회를 먼저 주는 것이다.
이 단계에서 track-detection 간 match 된 object 들은 kalman filter update 단계로 입력된다.
matching되지 않은 것들은 unconfirmed 로 분류되어 iou matching 단계로 넘어 간다.
IoU matching
IoU matching 은 처음 detection 된 이후 3frame 이 안된(= 처음 detecion 된 이후 track-detection 간 매칭이 3번이 안된 object들) object들의 kalman filter prediction 값과 cascade matching에서 track-detection간 matching되지 않은 object들을 인풋으로 IoU 를 매트릭으로 SORT 와 같은 방식으로 matching 한다.
IoU matching 단계에서 track-detection 간 matching 된 object들은 kalman filter update 단계로 입력 되고
unmatched detection 은 새롭게 detection 된 object 라는 의미에서 3 연속 프레임 동안 detction 되기 전까지 tentative 상태로 track에 추가된다.
unmatched track의 경우 age > 30 이면 frame 에서 떠난 것으로 판단하고 삭제 하고 age <= 30 이면 track에 그냥 남겨 놓는다.
운영 대상은 필자가 개발한 장고 앱으로 지인의 부탁으로 잘 모르지만 재능 기부(?) 로 개발을 하게 되었다.
필자는 DL/ML 엔지니어로 장고와 서버 운영의 전문가는 아니므로 본 포스팅은 불완전한 내용을 포함할 수 있다.
내용이 틀리거나 보완필요 한 부분이 있다면 댓글로 알려주면 좋을거 같다.
참고한 자료는 본 포스트의 끝에 있다.. 점프 투 장고 가 큰 틀에서 이 장고 앱 공개 과정을 이해하는데 가장 도움이 많이 되었다. 관심있는 분들은 읽어 보면 큰 도움이 될거 같다.
운영 계획은 아래와 같다.
필자의 컴퓨터에 django 앱과 DB(mysql)서버를 docker container 로 인스턴스화 해 운영하고
웹서버로 nginx, wsgi 서버로 gunicorn을 사용할 계획이다.
운영 환경
os: ubuntu 20.04
docker version: 20.10.18
Docker Compose version: v2.10.2
nginx: 1.18.0
gunicorn: gunicorn-20.1.0
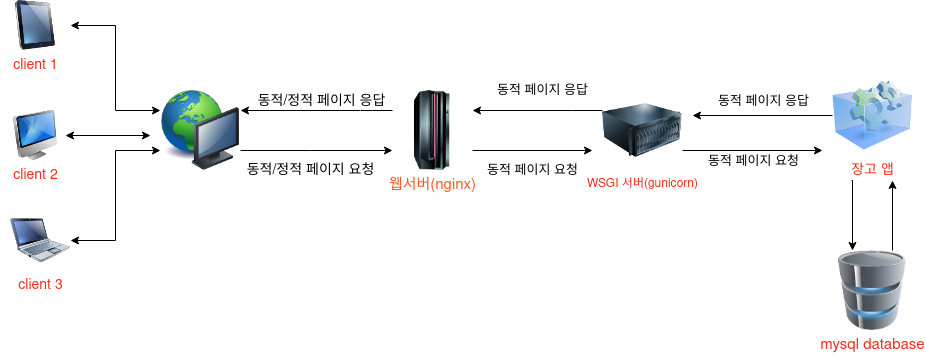
아래 그림은 운영 환경 다이어그램이다. 이 포스트에서는 아래 다이어그램 처럼 운영 되도록 nginx 와 wgsi서버를 설정 하는 것을 정리한다.
Fig 1. 운영 환경 다이어그램
WSGI 서버
WSGI 서버는 여러 종류가 있다고 하지만 편의상 gunicorn 을 사용 하기로 했다.
WSGI 서버의 역할을 Fig 1. 에서 보는 것처럼 동적 페이지 요청이 웹서버로 들어왔을 경우 웹서버의 호출에 응답해 장고 어플리케션을 호출하고 동적 페이지를 전달 받아 웹서버로 해당 응답을 전달한다.
웹서버가 장고 어플리케이션을 바로 호출하지 않고 WSGI 서버를 통해 처리 하는 이유는 웹서버는 python 어플리케이션인 장고 앱을 어떻게 호출하는지 모르기 때문이다.
장고 앱을 생성하면 기본적으로 장고 프로젝트의 config/wsgi.py라는 파일이 생성된다.
기본 내용은 아래와 같고 맨 아래 줄의 application 이 이 포스트에서 공개 운영하고자 하는 장고 앱이다.
참고: 개발과 운영시 setting을 분리해 사용 한다면 아래 os.environ.setdefault()의 두번째 인자로
운영을 위한 setting파일 경로를 넘겨 주거나 운영 환경에서 'DJANGO_SETTINGS_MODULE' 환경 변수를 따로 등록 해 사용해야 한다.
"""
WSGI config for config project.
It exposes the WSGI callable as a module-level variable named ``application``.
For more information on this file, see
https://docs.djangoproject.com/en/4.1/howto/deployment/wsgi/
"""
import os
from django.core.wsgi import get_wsgi_application
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings')
application = get_wsgi_application() #<<<<----- 이 애플리케이션이 공개 운영하고자 하는 장고 앱이다
gunicorn
설치:
pip install gunicorn
테스트:
운영하고자 하는 장고 앱 프로젝트 위치로 이동해 아래 명령을 입력한다.
필자의 경우 장고 앱 위치를 /home/pajama/jnbdrive 로 가정한다.
cd /home/pajama/jnbdrive
gunicorn --bind 0:7878 config.wsgi:application
--bind 0:7878 옵션은 7878포트로 들어 오는 요청을 처리 대상으로 하겠다는 것이고 config.wsgi:application 은 요청을 장고 앱이 confing.wsgi 파일에 정의된 application 이라는 의미이다.
실행하면 아래와 같은 내용이 terminal에 뜬다.
Fig 2. gunicorn 실행 정보
실행 정보를 보면 'Listening at: http://0.0.0.0:787' 이라는 내용으로 7878 포트로 들어오는 요청을 듣고 있다는 것을 확인 할 수 있다.
실행 후 운영하려는 대상 웹페이지에 접속하면 개발했던 것과 다르게 아래 와 같은 화면이 뜬다. 배경 같은 디자인적 요소가 적용이 하나도 안된 페이지 인데 이유는 gunicorn 이 정적 파일을 처리하지 못했기 때문이다. 내 운영 환경에서 gunicorn 은 동적 페이지 요청에 대해서만 담당하므로 이렇게 뜨는게 정상이다. 정적 파일과 관련된 것은 nginx 설정에서 다룬다.
Fig 3. 구니콘으로 실행한 운영 페이지
참고: 위의 예제 처럼 --bind 0:7878 로 포트를 설정해서 gunicorn 을 운영 할 수 있지만 포트를 이용하는 것은 느려서 비효율 적이라고한다.(점프 투 장고에서 봤다.) 유닉스 계열에서는 유닉스 소켓을 이용해 하는 것이 더 빠른 성능을 기대 할수 있다고 한다.
위 심볼릭 싱크를 만들어 주면 nginx의 기본 환경 설정 파일인 /etc/nginx/nginx.conf이 위 심볼릭 링크 설정 파일에 정의된 서버 설정을 기반으로 동작 해 192.168.0.102 로 들어오는 요청을 /etc/nginx/sites-available/jnbdrive 의 server 모듈에서 정의한 대로 처리 해 준다.
참고: 성능 최적화를 위해서는 /etc/nginx/nginx.conf 파일 설정도 변경 필요한 경우가 있으므로 위 파일의 내용도 공부해봐야 한다.
정의한 /etc/nginx/sites-available/jnbdrive 내용을 nginx 에 적용하기 위해서는 아래 명령을 터미널에 입력한다.
systemctl restart nginx
nginx 파일에서 오류가 발생하면 다음과 같이 nginx -t 를 입력해 확인할 수 있다.
Fig 5 nginx -t 결과
issue 1.nginx 실행 시 '40: Too many levels of symbolic links' 에러가 발생한 경우는 심볼링 링크를 만들때 source나 link_name에 절대 경로가 아닌 상대 경로를 사용한 경우로 심볼릭 링크를 제거 하고 다시 만들면 된다.
vscode 로 jetson xavier 에 띄워논 docker container에 연결해 작업 하던 어느날 갑자기 아래 와 같은 에러가 발생했다.
Traceback (most recent call last):
File "/root/.vscode-server/extensions/ms-python.python-2022.12.0/pythonFiles/run-jedi-language-server.py", line 9, in <module>
from jedi_language_server.cli import cli
File "/root/.vscode-server/extensions/ms-python.python-2022.12.0/pythonFiles/lib/jedilsp/jedi_language_server/cli.py", line 7, in <module>
from .server import SERVER
File "/root/.vscode-server/extensions/ms-python.python-2022.12.0/pythonFiles/lib/jedilsp/jedi_language_server/server.py", line 14, in <module>
from pydantic import ValidationError
File "/root/.vscode-server/extensions/ms-python.python-2022.12.0/pythonFiles/lib/jedilsp/pydantic/__init__.py", line 2, in <module>
from . import dataclasses
File "/root/.vscode-server/extensions/ms-python.python-2022.12.0/pythonFiles/lib/jedilsp/pydantic/dataclasses.py", line 3, in <module>
from .class_validators import gather_all_validators
File "/root/.vscode-server/extensions/ms-python.python-2022.12.0/pythonFiles/lib/jedilsp/pydantic/class_validators.py", line 8, in <module>
from .errors import ConfigError
File "/root/.vscode-server/extensions/ms-python.python-2022.12.0/pythonFiles/lib/jedilsp/pydantic/errors.py", line 5, in <module>
from .typing import display_as_type
File "/root/.vscode-server/extensions/ms-python.python-2022.12.0/pythonFiles/lib/jedilsp/pydantic/typing.py", line 23, in <module>
from typing_extensions import Annotated, Literal
File "/root/.vscode-server/extensions/ms-python.python-2022.12.0/pythonFiles/lib/jedilsp/typing_extensions.py", line 159, in <module>
class _FinalForm(typing._SpecialForm, _root=True):
AttributeError: module 'typing' has no attribute '_SpecialForm'
[Error - 1:47:07 PM] The Python Jedi server crashed 5 times in the last 3 minutes. The server will not be restarted. See the output for more information.
[Error - 1:47:07 PM] Server initialization failed.
Message: Pending response rejected since connection got disposed
Code: -32097
[Error - 1:47:07 PM] Python Jedi client: couldn't create connection to server.
Message: Pending response rejected since connection got disposed
Code: -32097
[Error - 1:47:07 PM] Restarting server failed
Message: Pending response rejected since connection got disposed
Code: -32097
위 에러는 vscode의 python extension과 관련된 error로
python, pylance라는 두 extension 을 설치 한 후 발생했다.
관련된 증상으로는 python extension 이 정상 설치가 안되서 인지 python debuging 이 되지 않는다.
일반적 솔루션
이 현상에 대한 일반적인 솔루션은 이 사이트에 나온것 처럼 vscode의 setting에서
파일 -> 기본설정->설정->확장->python:Language Server의 값은 Pylance 나 Default 로 바꾸는 것이다.
하지만 나의 경우 이 일반 적인 솔루션은 의미 없었다.
내 솔루션
나의 경우 jetson xavier내의 python 버전이 3.6이었는데 최신 vscode python extension과 버전 호환이 잘 되지 않는 문제가 있었던 것으로 보인다.
해결 책으로 python과 pylance extension의 버전을 2022.04.1 버전(현재 최신은 2022.12.0)으로 롤백했더니 해결되었다.