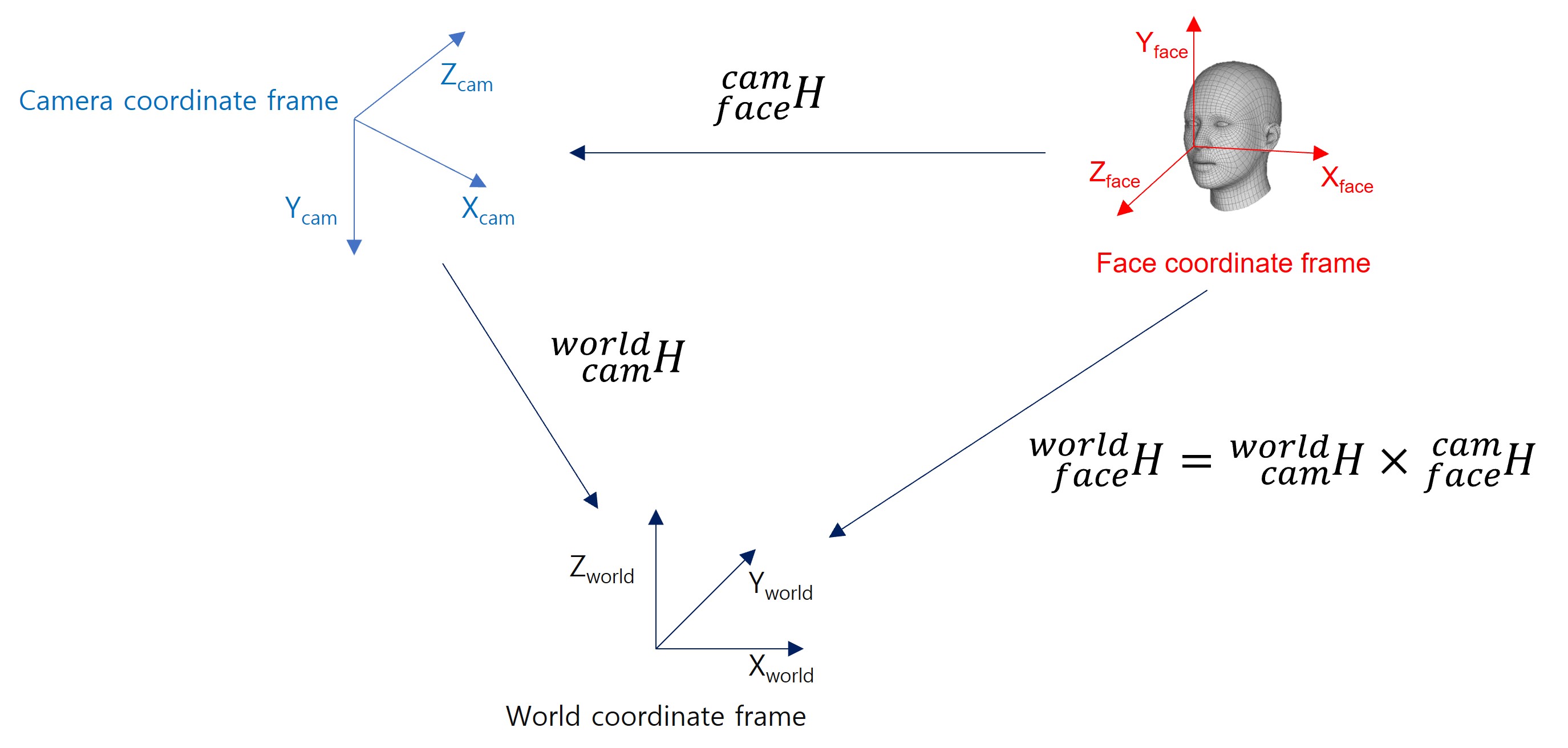
이 식을 least square 로 풀면 Pose $X^{face}_{camera}$ 의 추정 오차 공분산은
$C_{x} = E[\Delta X \Delta X^{T}] = (M^{T}M)^{-1}M^{T}E(\Delta p \Delta p^{T})((M^{T}M)^{-1}M^{T})^{-1}$
$E(\Delta p \Delta p^{T}) : ^{camera}_{face}H 를 이용해 projection 한 point의 공분산 행렬$ 로 나타낼 수 있다.
$C_{x}$는 6x6 사이즈의 행렬이다.
World-camera 의 추정 오차 공분산 행렬도 $C_{w} = 6 \times 6$ 이고 위와 동일 한 방식으로 calibration target을 이용해 구할수 있다.
최종 $^{world}_{face}H$의 추정 오차 공분산을 $C_{y}$ 라 하면
$X^{face}_{world}=f^{-1}(^{world}_{face}H)$
$^{world}_{face}H= ^{world}_{camera}H \times ^{camera}_{face}H = f(X^{camera}_{world}) \times f(X^{face}_{camera})$ 관계에 의해 공분산 전파(propagation) 식에 의해 아래와 같이 구할 수 있다.
$V_{gaze} =\begin{bmatrix} g_{x}\\g_{y}\\g_{z} \end{bmatrix}: gaze direction vector, ^{world}_{face}R의 마지막 컬럼, 즉 ^{world}_{face}H[:,2] = f(X^{face}_{world})[:,2]$
$p_{face} = \begin{bmatrix} x_{face}\\y_{face}\\z_{face} \end{bmatrix}$, 얼굴 위의 한점 여기선 face coordinate frame origin의 world coordinate frame 상의 좌표로 설정, 즉 $^{world}_{face}H[:,3]=f(X^{face}_{world})[:,3]$
이때 $V_{gaze}$는 시선의 방향을 나타네는 벡터 즉 시선의 방향 벡터라고 볼 수 있다. 가정에 의해 시선의 방향은 얼굴 평면과 수직(perpendicular) 이므로 world 좌표계에서 head pose를 나타내는 rotation matrix의 3번째 컬럼 즉 face coordinate frame의 z axis에 해당한다. 3차원 공간상에서 방향벡터 $V$와 평행하고 사람의 얼굴 위의 한점(눈 사이의 한점을 잡는게 가장 좋으나 여기서는 코끝으로 가정했다.)을 지나는 직선을 구하는게 목적이므로 $p_{face}$는 코끝의 world coordinate frame 상의 좌표로 가정하자.
이렇게 하면 world coordinate frame 상의 z-x평면위에서 이미지 상의 특정 인물이 바라보고 있는 좌표(gaze point)와 불확실성은 아래와 같이 구할 수 있다.
$t= -\frac{p_{face}}{g_{y}} $ 로 설정 하면 y=0이 되므로 world 좌표계 상에서 x,z평면과 만나는 gaze point를 구할 수 있고
gaze point 와 pose $X^{face}_{world}$의 관계에 따라 gaze point 의 공분산은
self-attention-based 모델은 컨볼루션 네트웍의 대안이다. ViT 계열의 트랜드는 모델 파라미터를 늘려서 성능을 끌어 올리는 방식인데 이는 모델 사이즈를 키우고 latency를 증가시킨다. 따라서 edge device 같은 자원이 제한적인 환경에서 이는 문제가 된다.
mobile device의 자원 제약을 충족할 정도로 Vit 모델 사이즈가 줄어 들 수 있지만 DeIT(Touvron et al., 2021a) 의 경우에서 보이듯 light-weight CNN(MobileNetV3)보다 3% 낮은 성능을 보일 정도로 성능하락이 심하다.
Vit 계열의 문제점은 1. 모델이 무겁다.ex) ViT-B/16 vs mobileNetV3: 86 vs 7.5 million parameters 2. 최적화 하기 어렵다(Xiao et al., 2021 ) 3. 오버 피팅을 방지 하기 위해 광범위한 Data augmentation 과 L2 regularization 이 필요하다. (Touvron et al., 2021 a; wang et al., 2021) 4. dense prediction taskex) segmentation,과 같은 down-stream task 를 위해 무거운 decoder가 필요하다. (ex. Vit-base 세그멘테이션 네트웍(Ranftl et a. 2021.,) 은 345 million parameters를 사용해 CNN계역의 DeepLabv3(59 million parameters)와 비슷한 성능을 얻었다.)
ViT 가 비교적 많은 파라미터를 필요로 하는 것은 CNN 계열이 선천적으로 지니고 있는 image-specific inductive bias가 부족하기 때문으로 보인다. (Xiao et al., 2021)
강인한 고성능 Vit 모델 개발을 위해 convolution과 transformers의 결합이 주목받고 있다. (xiao et al., 2021, d'Ascoli et al., 2021; Chen et al., 2021b). 그러나 이런 모델은 여전히 무겁고 data augmentation 에 예민하다. 증거로, Cutmix와 DeIT-style data augmentation 을 제거하면 Heo et al(2021)은 imageNet accuracy가 78.1% 에서 72.4% 로 감소한다.
이러한 이유로 CNN과 transformer의 강점을 조합해 mobile vision task를 위한 ViT 모델을 만드는 것은 여전히 숙제로 남아있다.(본인들 연구 정당성을 이렇게 정성들여 조목조목 주장할 수 있는 건 정말 큰 능력인것 같다.)
이 논문에서 저자는 light-weight, general-purpose, low-latency이 3가지 관점에 초점을 맞춰 mobilevit라는 모델을 제안한다.
여기서 low-latency와 관련해 FLOPs라는 지표가 적절하지 않다고 언급하는데 이유는 다음과 같다.
FLOPs는 아래와 같은 latency에 영향을 미치는 요소들을 고려하고 있지 않다. 1. 메모리 엑세스 2. 병렬성 정도 3. 플랫폼 특성 그 증거로 PiT는 DeIT 에 비해 1/3배의 FLOPs 를 가지고 있으나 iPhone-12에서 비슷 한 latency를 보여준다. (10.99ms vs 10.56ms) 따라서 이 논문은 FLOPs 측면에서의 최적화를 목표로 하지 않는다. (즉, FLOPs는 상대적으로 큰 편이다...)
정리: MobileVit는 CNNs의 장점인 spatial inductive biases 와 less sensitivity to data augmentation 과 ViT의 장점인 input-adaptive weighting and global processing을 잘 조화했다.(가 주장하는 바이다.)
특히 MobileVit block를 제안하는데 이 블럭은 local 과 global information 모두를 tensor 효율적으로 encode 한다. (한글로 풀어 쓰고 싶은데 표현하기 정말 난해 하다...) Convolution을 사용/사용 하지 않는 ViT 계열과는 다르게, mobileVit는 global representation을 학습하는데 다른 관점을 지니고 있다. standard 컨볼루션은 3개 연산으로 이루어 진다. unfolding, local processing, folding. MobileVit Block은 local processing을 transfomer를 이용한 global processing으로 치환해서 CNN과 ViT의 특성을 가진다. 그로인해 적은 수의 파라미터와 간단한 학습 레시피(data augmentation이 ViT에 비해 간단함을 의미) 더 좋은 feature를 배운다.
결과적으로 MobileViT는 5~6million의 파라미터 수로 mobileNetV3보다 3.2% 더 높은 Top-1 accuracy를 ImageNet-1k dataset에서 보여 준다.
기존 모델들의 한계:
light-weight cnn:
공간적으로 local information에 의존한다. Convolution 필터 자체가 인접 픽셀들간의 관계로 부터 representation을 학습하니 당연하다. 다만 layer가 깊어 질수록 receptive field가 커짐에도 불구하고 이렇게 표현한 걸 보면 상대적으로 local 하다는 표현인것 같다.
Vision transformer:
많은 파라미터를 사용한다. 데이터가 크지 않으면 오버피팅 문제가 있다. extensive data augmentation 이 필요하다. convolution을 이용하는 ViT 모델들도 있지만 여전히 heavy weight이고 light-weight CNN 모델들 수준으로 파라미터 수를 줄이면 CNN 계열 보다 성능이 떨어지는 문제를 한계로 지적했다.
ViT 계열은 image-specific spacial inductive bias가 부족 하기 때문에 더 많은 파라미터와 data augmentation이 필요하다고 언급하는데 convolution을 ViT에서 이용 함으로서 이 부족한 inductive bias를 ViT 모델에 이식할 수 있다고 한다.
논문에서 언급된 여러 모델들이 convolution을 ViT 모델에 서로 다른 방식으로 이용해 CNN과 ViT의 장점을 이용해 강건하고 고성능의 ViT 만들었다고 한다. 하지만 여전히 남은 문제는 "convolution과 ViT를 어떻게 조합해야 둘의 강점을 잘 이용 할수 있는가?" 라는 점이다.
위와 같은 문제를 가지고 있는 기존 방식에 비해 MobileVit의 강점은 :
1. Better performance(주어진 파라미터 한계에서 light-weight CNN 보다 높은 성능을 보임) 2. Generalization capability: 다름 ViT variant 모델들 모다 generalization capability가 좋음 3. Robust: Data augmentation과 L2 regularization에 덜 민감함
MobileViT block:
이 논문의 핵심은 MobileViTBLock을 통해 적은 수의 파라미터로 local 과 global information을 modeling 하는 것이다.
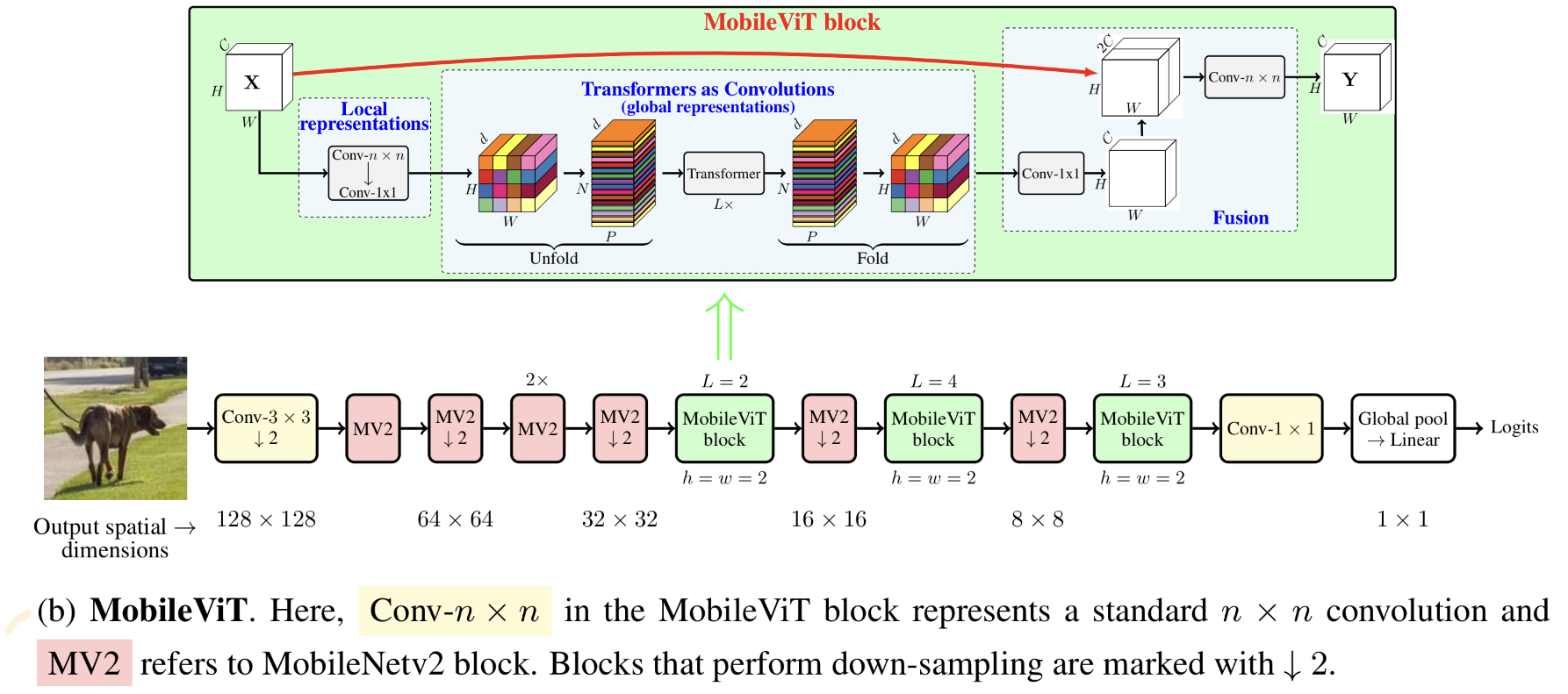
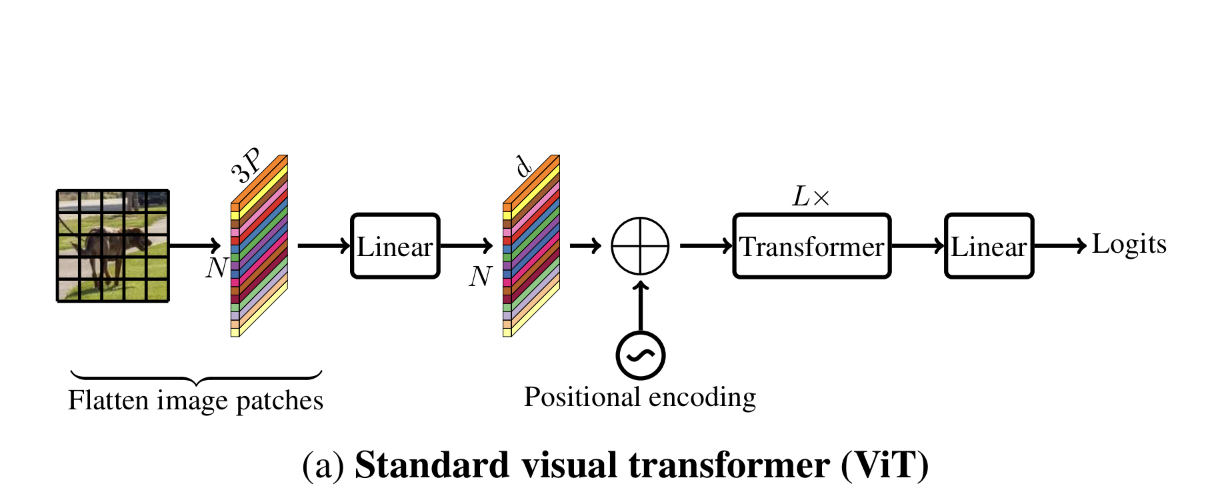
Fig 1. MobileViT Diagram
Fig 1 의 녹색 영역은 MobileViTBlock의 연산을 도식화한 것이다. MobileVitBlock에서 local spacial information ( Fig 1 녹색 영역의 Local representations 로 표시된 부분)은 $n \times n$ convolution을 이용해 획득하고 point-wise convolution을 이용해 인풋 텐서 채널의 선형 조합으로 고차원 정보를 생성한다. --------------------------------------------------------------------------------------(1)
global information은 multihead attention을 이용해 학습하게 된다.
input을 $X_L$이라 할때 $X_L$을 서로 오버랩 되지 않는 patch $X_U = R^{P \times N \times d}$ 로 나타낸다. $P = w \times h$ 로 h,w는 패치의 가로,세로 크기 이고, $N=\frac{HW}{P}$은 input tensor내에 존재하는 패치의 수이다.
transformer가 local spatial information과 inter_patch 정보를 모두 모델링 하기 위해서는 h<=n, w<=n 을 반드시 만족해야 한다. 즉 non-overlap 패치의 크기는 convolution kernel의 크기보다 반드시 같거나 작아야 한다.
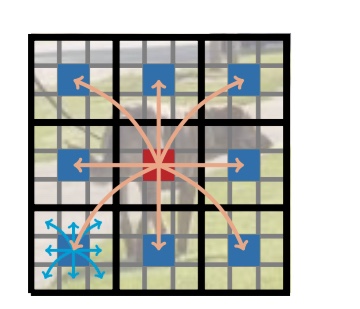
아래 그림 Fig 2는 MobileViTBlock 이 왜 local 과 global representation을 모두 학습 할 수 있는 지 보여준다. 검은 색 굵은 선으로 분리된 각 영역은 오버랩되지 않은 patch이고, 각 patch 내 회색 선으로 분리된 공간은 patch에 속하는 pixel 이라 보면 된다. 왼쪽 하단의 patch를 보면 파란색 화살표가 파란색으로 표시된 pixel 주변의 정보를 취학하는 것을 표현 했는데 이는 $ n \times n$ convolution을 통해 이루어 진다. 아래 그림의 정가운데 위치한 patch 내에 붉은 색으로 표시된 pixel은 다른 patch의 자신과 동일 한 위치의 pixel들의 정보를 취합 하는데 이과정이 multi-head attention을 통해 이루어 진다.
Fig 2. How local and global representation are learned by MobileVitBlock
이를 좀더 수식 적으로 표현 하면 $p = {1,...,P}$ 라 할때 패치간의 관계는 모델은 다음과 같이 표현 할 수 있다. $$ X_{G}(p)=Transformer(X_{U}(p)), 1<=p<=P$$ ViT와 다르게, 위와 같이 모델링 되는 MobileVit는 패치간의 순서나 pixel의 공간 정보도 잃지 않기 때문에 MobileVitBlock의 입력 $X_{L}$의 각 픽셀 위치에 해당하는 local, global information이 축약된 정보를 입력 모양에 맞게 $X_{F}=R^{H \times W \times d}$로 복원가능 하다. 그 후 $X_{F}$는 point-wise-convolution을 이용해 저차원으로 projection 되고 mobileVitBlock의 입력 X와 concat된 후 $n \times n$ convolution을 이용해 feature를 혼합한다.
$X_{U}$은 $n \times n$ convolution으로 local information을 학습하고 $X_{G}$는 패치간의 정보를 취합하기 떄문에 $X_{G}$의 각 픽셀은 결국 입력 X의 모든 정보를 취합한다고 볼수 있다. (코드 상으로 보면 X_G의 임의의 패치 p에 속한 임의의 pixel i(hi,wi)는 X_G의 오버랩 되지 않는 p가 아닌 다른 패치들의 q에 속한 pixel j(hi,wi)위치와 attention이 계산되므로 엄밀히 말하면 모든 픽셀에 대한 정보를 취합하는 것이 아니라 다른 패치 내의 동일한 위치에 있는 pixel의 정보만 취합한다. 따라서 입력 X의 모든 픽셀에 대한 정보를 X_G가 취합 하게 하려면 nxn convolution의 커널 사이즈 n와 , 패치 사이즈 h,w를 신중하게 디자인 해야 한다. )
코드로 보면 더 직관 적이니 아래 코드를 보자. 각 라인 옆에 위 설명의 $X_{L}$, $X_{U}$, $X_{G}$에 해당 하는 값을 표기해 두었다.
class MobileViTBlock(nn.Module):
def __init__(self, dim, depth, channel, kernel_size, patch_size, mlp_dim, dropout=0.):
super().__init__()
self.ph, self.pw = patch_size
self.conv1 = conv_nxn_bn(channel, channel, kernel_size)
self.conv2 = conv_1x1_bn(channel, dim)
self.transformer = Transformer(dim, depth, 4, 8, mlp_dim, dropout)
self.conv3 = conv_1x1_bn(dim, channel)
self.conv4 = conv_nxn_bn(2 * channel, channel, kernel_size)
def forward(self, x):
y = x.clone()
# Local representations
x = self.conv1(x)
x = self.conv2(x) # 여기서 x = X_L 이다.
# Global representations
_, _, h, w = x.shape
x = rearrange(x, 'b d (h ph) (w pw) -> b (ph pw) (h w) d', ph=self.ph, pw=self.pw)
x = self.transformer(x) # 파라미터 x = X_U 이고 output x = X_G이다.
x = rearrange(x, 'b (ph pw) (h w) d -> b d (h ph) (w pw)', h=h//self.ph, w=w//self.pw, ph=self.ph, pw=self.pw)
# 바로 윗 라인의 reshaped 된 x = X_F에 해당 된다.
# Fusion
x = self.conv3(x)
x = torch.cat((x, y), 1)
x = self.conv4(x)
return
relationship to convoltuions:
컨볼루션은 아래와 같은 3개 연산의 스택으로 볼 수 있다. Fig 1 의 녹색 영역을 참고해서 보면 좀더 쉽게 이해 할 수 있다. 1. unfold 2. matrix multiplication 3. fold 본 논문에서 제시한 mobileVitBlock는 아래와 같은 3단계 연산을 한다는 측면에서 transformer를 convolution 처럼 본다고 볼수 있다. 1. 입력 $X_{L} \in \in R^{H \times W \times d}$을 non-overlaping patch $X_{U} \in R^{P \times N \times d}$로 unfolding 하고 -> convolution의 unfolding에해당 2. transformer layer를 통해 global representation을 배우고 -> convolution의 matrixmultiplication에 해당 3. transformer의 output인 $X_{G} \in R^{P \times N \times d}가 patch order와 pixel order를 잃지 않았기 때문에 $X_{F} \in R^{H \times W \times d}$로 복원 -> convolution의 folding에 해당
개인 적으로 transformer를 convolution 처럼 볼수 있다는 해석 보다 non-overlaping 패치 간의 feature relation을 모델링 하기 위해 swin transformer 가 axis roll 을 사용 한것 보다 본 논문에서 convolution과 transformer 블럭을 사용해서 local, global feature representation을 학습하는 전략이 더 간단하고 효과적으로 보인다.
light-weight:
기존 convolution + transformer 사용 네트워크가 heavy했기 때문에 같은 레이어의 조합을 사용하는 MobileViT가 왜 light-weight 이 가능 한지 의문이 들 수 있다. 저자는 그 이유를 다음과 같이 말한다. 기존의 convolution과 transformer를 사용하던 네트워크는 spatial information을 latent로 바꾼다. 이게 무슨 말인고 하니 아래 그림 Fig 3을 보자.
Fig 3.
transformer 적용시 인접 픽셀을 채널축으로 stack 하고 픽셀 값들을 linear 연산을 이용해 latent로 보내는 embeding 연산이 image-specific inductive bias를 잃게 하는데 반해 MobileViT는 convolution과 transformer를 convolution의 특징을 살리면서 global representation을 배울 수 있는 방향으로 사용하기 때문에 light weight이 가능 하다는 입장이다.
Multi-head self-attention의 계산 복잡도를 비교해 보면 MobileViT: $O(N^{2}Pd)$ ViT: O(N^{2}d) 로 MobileViT가 더 비효율 적으로 보인다. 하지만 실제로는 MobileViT가 DeIT보다 약 1/2배의 FLOPs 를 가지고 ImageNet-1K 에서 1.8%더 높은 accuracy를 보였다. 이럴수 있는 이유 역시 convolution과 transformer를 서로의 장점을 살리는 방식으로 조합했기 때문에 가능했다는 것이 논문의 주장이고 결과가 좋으니 맞는 말로 보인다.
Multi-Scale Sampler For Training Efficiency:
MobileViT를 학습 시키기 위해 multi scale training 전략을 사용 했는데 기존 방식과 크게 두가지 다른점 이 있다. 이 두가지 다른점은 기존 multi-scale training 방식의 다음과 같은 단점을 보완한 것이다.
1. ViT 계열 네트워크는 multi scale training을 위해 각 scale 별로 네트워크를 fine tuning 하는 방식을 취한다. 왜냐면 ViT의 positional embedding이 입력 이미지 사이즈에 따라 interpolation 되어야 하고 네트워크의 성능이 이 positional embedding의 interpolation 방식(?) 에 영향을 받기 때문이다.
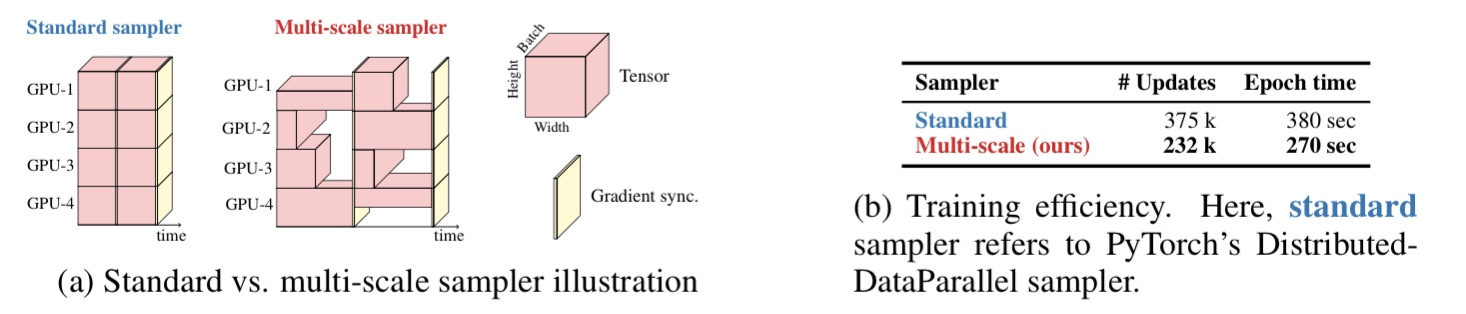
2. CNN 계열 네트워크들은 학습 중 미리 정해진 입력 이미지의 사이즈 $set S=((H_{0},W_{0}), ..., (H_{n}, W_{n}))$중 하나를 정해진 iteration 마다 선택해 학습에 활용하는데 이렇게 하면 batch size가 가장 큰 입력 이미지 사이즈에 의해 고정적으로 결정되기 때문에 작은 입력 이미지 사이즈를 이용해 학습할 때는 GPU 사용율이 떨어질수 밖에 없다. Fig 4 (a) 의 Multi-scale sampler를 보면 여기서 지적한 문제를 도식화 했다. Standard sampler에 비해 gpu memory utilization이 떨어지는 것을 표현했다.
위 두 가지 문제를 해결하는 multi scale sampling scheme은 다음과 같다. 1. MobileViT의 경우 positional embedding이 필요 없기 때문에 파인튜닝 방식으로 multi scale training scheme을 사용 할 필요 없이 CNN 계열 네트워크 처럼 학습 중 기 정해진 방식으로 multi scale training을 사용 한다.
2. 기존 방식에 존재 하던 비효율적 batch size 선택을 개선하는 방법으로 가장 큰 입력 이미지 사이즈를 $(H_{n}, W_{n})$, 이때의 batch size 를 b 라 할때 i-th iteration의 배치 사이즈 $b_{t}$ 는 $b_{t} = \frac{H_{n} * W_{n} * b}{H_{i}*W_{i}} 를 사용하게 함으로써 gpu utilization 문제를 해결한다. 결과적으로 위와 같은 2가지 보완점을 적용한 multi-scale sampler를 사용 할 경우 Fig 4 (b) 같이 standard sampler 보다 학습 효율이 좋아지는 것을 볼 수 있다.
Fig 4. About Multi scale sampler
Experimental result:
Dataset: image classification on The ImageNet-1k Dataset implementation details: MobileVit를 from scratch로 imageNet-1k 에 학습 시킴, 1.28 million training image, 50,000 validation image. GPU: 8 NVIDIA GPU 사용 framework: pytorch batch size: 1024 epoch: 300 기타 : label smoothing cross-entropy(smoothing=0.1), multi-scale sampler(S={(160,160), (192,192), (256,256), (288,288), (320, 320)}, L2 waeight dacay( 0.01), lr scheduler: consine annealing (0.0002~0.002 warm start)
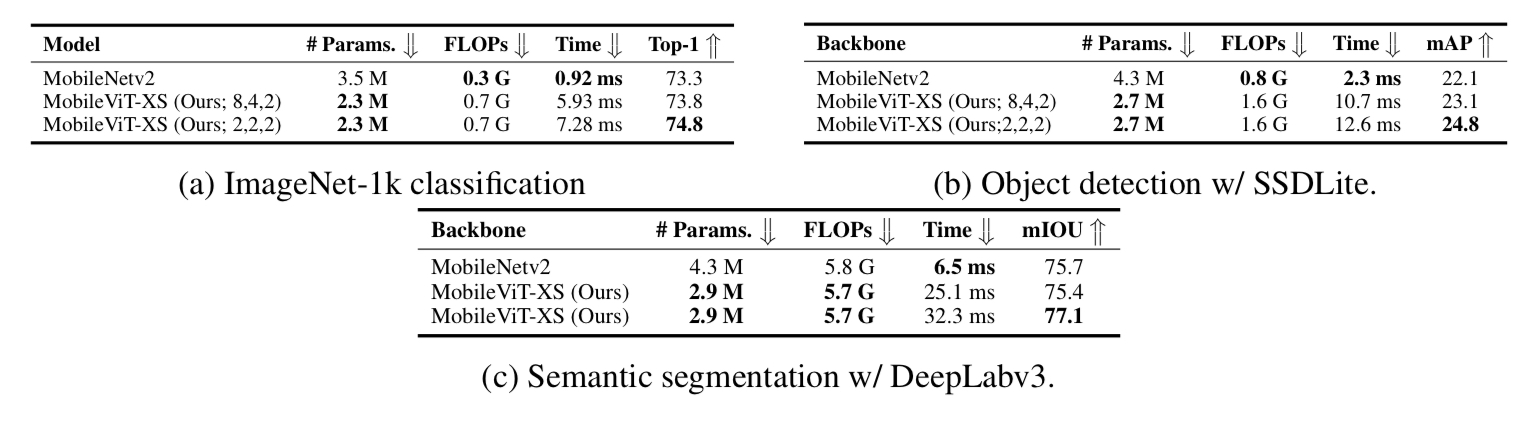
CNN모델들과 비교 :
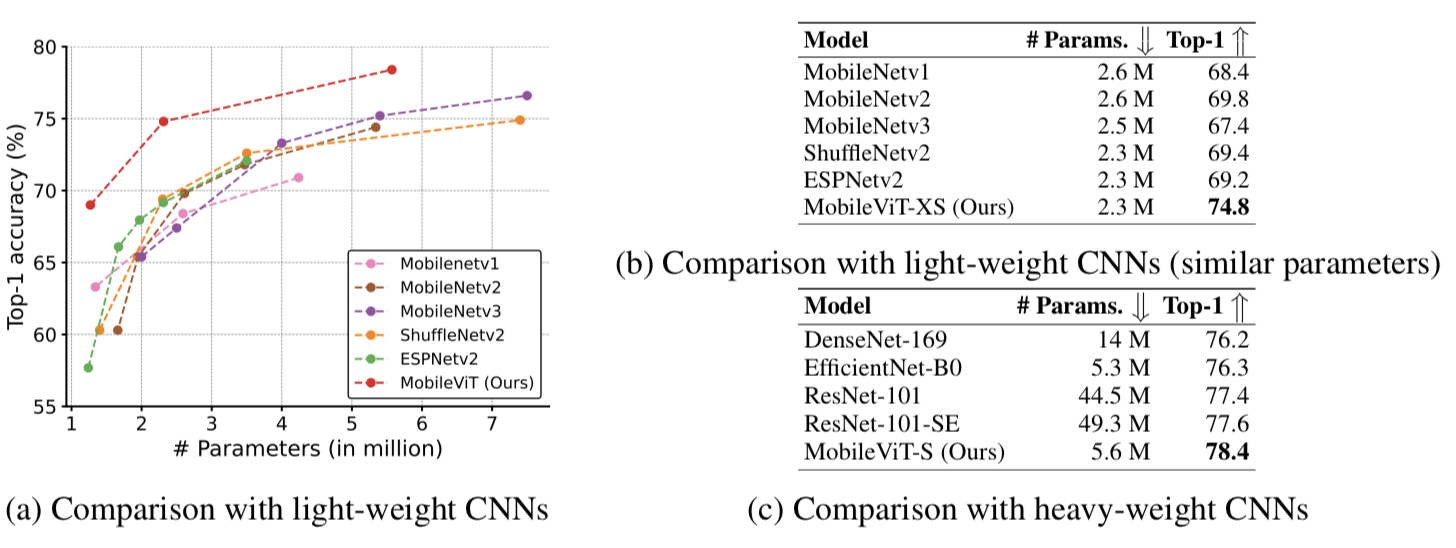
Fig 5 CNN 계열 네트워크와의 비교
Fig 5에서 볼 수 있듯 MobileViT는 light-weight CNN들 보다 우수한 성능을 보여준다. Fig 5 (b)를보면 MobileViT-XS모델은 파라미터 수는 가장 작지만 top-1 acc 는 가장 높은 성능을 보여 준다. 심지어 Fig 5 (c)를 보면 heavy-weight CNN 네트워크와 MobileViT-S 모델을 비교 해도 상대적으로 작은 파라미터 수로 높은 top-1 acc 성능을 보여 준다.
ViT와 비교:
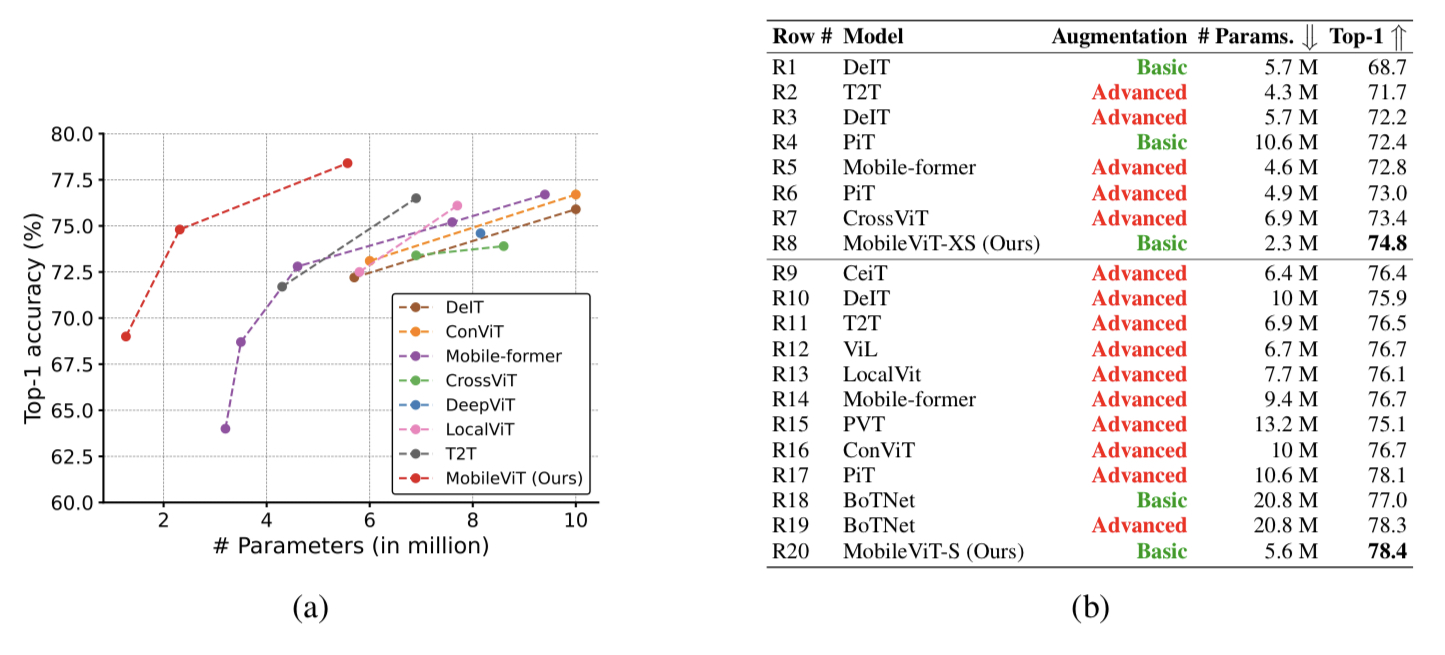
Fig 6. ViT 계열 네트워크와의 비교
CNN 계열 네트워크 들과 비교 결과와 거의 유사하다. Fig 6 (a), (b)에서 볼수 있듯이 MobileViT-XS, MobileViT-S 모델은 다른 ViT 모델들 보다 상대적으로 적은 파라미터 수로 더 좋은 top-1 acc 성능을 달성했다. 비교를 위해 ViT 계열 모델들 학습시 advenced augmentation사용, distillation 비사용, MobileVit는 basic augmentation을 사용했다.
Object detection 과 Segmentation:
아래 그림 Fig 7에서 보듯이 MobileViT는 object detection 과 segmentation task에서도 backbone으로서의 역할을 수행 할수 있고 성능 또한 MobileNetV2에 비해 좋은 결과를 보여준다. 단 inference time이 mobileNetv2가 압도적인 것으로 보이는 데 이것은 MobileNetV2 의 연산은 하드웨어 최적화가 잘되어있기 때문으로 논문의 appendix에 이 부분에 대한 분석이 포함되어있다. 꼭 읽어 보길 바란다. (사실 이유는 이미 언급했듯이 mobilenetv2는 하드웨어 최적화가 잘되어있기 때문으로 MobileViT의 연산을 효율적으로 지원하는 하드웨어 가속기가 존재한다면 MobileViT의 속도도 훨씬 빨라질 것이라고 하는데 이는 모든 구조가 다 마찬가지 아닌가 하는 생각..)
Fig 7 테스크 별 MobileViT 적용 성능
생각 해 볼만 한 사실들
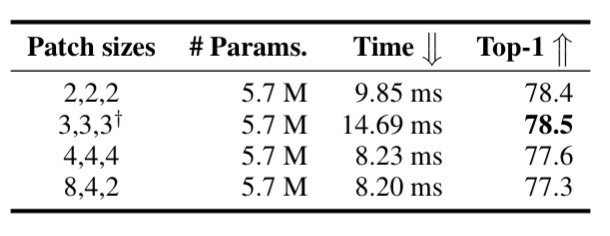
Patch Size:
아래 그림 Fig 8 은 patch size 에 따른 inference 속도 변화 와 acc 성능 변화를 보여준다. patch size 에 따라 inference 속도와 acc 성능 변화가 나타나니 응용에 따라 주의 깊은 튜닝이 필요할 것 같다.
Fig 8 패치 사이즈 별 inference 속도와 분류성능 관계 patch 사이즈는 각각 32x32,16x16,8x8 의 spatial level에 해당
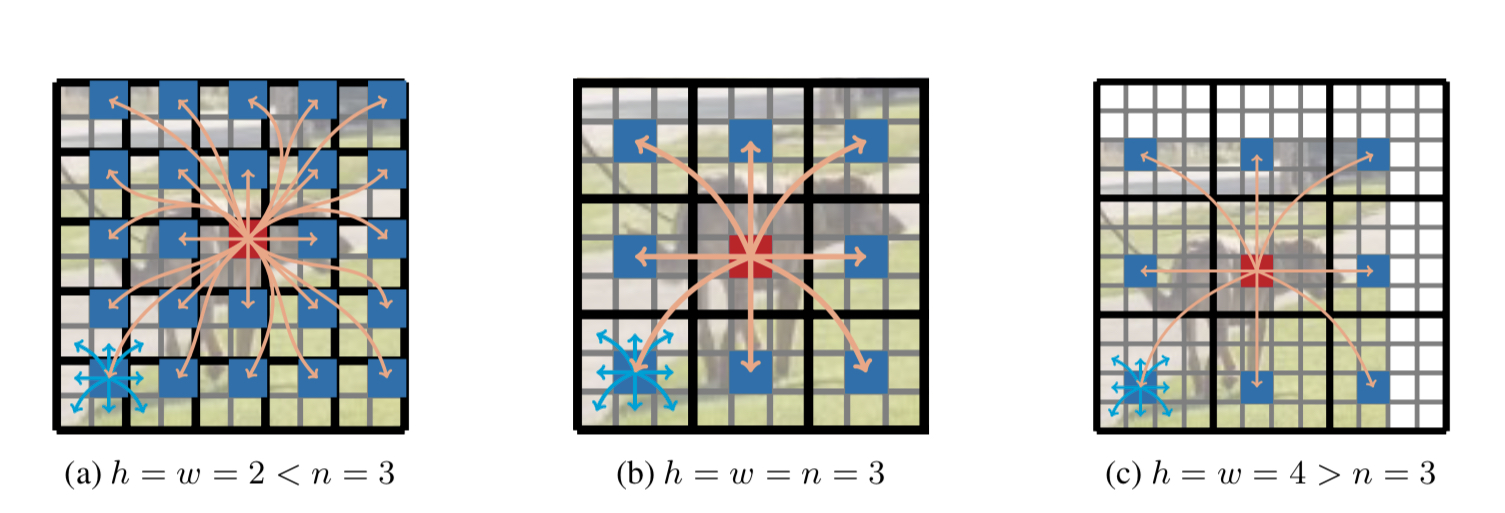
$nxn$ convolution kernel size 와 patch size ($ h \times w$)의 관계:
아래 그림 Fig 9에서 n은 convolution kernel의 크기, h,w는 patch 의 크기를 나타낸다.
Fig 9 patch 사이즈와 convolution kernel 사이즈의 관계
$h or w > n$ 일 경우 Fig 9 (c) patch 내의 각 pixel은 해당 convolution을 통해 patch 에 속한 모든 pixel의 정보를 취합 할 수 없으므로 local information의 취합 능력이 떨어진다. 이는 곳 전체 적인 성능 하락으로 이어진다.
Inference speed:
논문의 제목에서 알 수 있듯이 MobileViT는 edge device 에서 효율과 성능이 좋은 network를 목표로 했다. 하지만 아래 표 에서 보이듯 실제 iPhone 12 cpu, iPhone12 neural engine, NVIDIA V100GPU 에서 inference time을 비교 해보면 MobileNetv2가 위 언급된 모든 device에서 가장 빠르다.
iPhone에선 MobileViT는 DeIT, PiT 보다는 빠르지만 GPU 에서는 DeIT, PiT 가 오히려 빨랐다. GPU에서 MobileViT가 DeIT, PiT 보다 느린 이유는 1) MobileViT 모델이 shallow 하고 narrow 한 특성이 있고, 2) 256x256 이라는 좀더 큰 해상도 (DeIT는 224x224)로 동작 하기 때문이라고 한다. 또한 MobileViT 의 MobileViTblock 에서는 unfolding, folding 연산(Fig 1 참조)이 수행되는데 V100에서 이 두 연산을 gpu -accelerated operation을 사용 하는지 안하는 지에 따라 그 결과가 다르다. gpu -accelerated operation 을 사용 하지 않을 경우 0.62ms 이 걸리고 사용할 경우 0.47ms 이 걸린다. 그리고 MobileNetv2의 inference 속도가 빠른 이유는 mobileNetv2를 구성하는 연산을 서포트 하는 하드웨어 가속기의 덕분일 것으로 본다. MobileViT에 사용 되는 연산들이 하드웨어에 최적화되게 구현된다면 mobieViT의 inference 속도도 더 높아 질수 있을 것이라고 저자는 말한다.
mlflow 의 backend store 로 mysql server를 사용 중 artifact 저장 path 가 바뀌어 이를 수정 하는 도중
문제가 발생해 이를 해결한 과정을 정리한다.
같은 상황에 처하게 될지 모를 미래의 나 자신과 비슷 한 상황에 처할지 모를 누군가에게 도움이 되길 바란다.
환경 정보:
PC1 host os: ubuntu 2004
PC1 docker version:
PC1 docker compose version:
PC1 mysql server image: mysql/mysql-server:8.0.28
PC1 mlflow version:1.24.0
PC2 host os: ubutu 18.04
PC2 docker version:
PC2 docker compose version:
PC2 mysql server image: mysql/mysql-server:8.0.28
PC2 mlflow version: 1.24.0
이슈 발생 상황:
이슈 발생 원인은 복합적이다.
복잡할 수 있지만 정확하게 정리하고 기록하기 위해 상황을 설명한다.
상황은 아래와 같다.
나는 Fig 1. (A) 와 같은 pc1(내 주사용 pc)에 mlflow tracking server, mysql server를 운영 중이었다.
mlflow tracking server 와 mysql server는 각각 docker container 로 instance화해 운영하고 mysql은 mlflow의 backend store로 NAS에 있는 특정 directory를 artifact uri로 사용하고 있었다.
그러던 중 놀고 있는 pc2를 발견하고 pc2에 mlflow tracking server와 mysql server를 운영 하면 내 주pc 인 pc1은 한결 가볍게(필요할때 재부팅 등) 사용 할 수 있기에 Fig 1. (B) 처럼 pc2로 서버를 운영 하고 pc1은 학습에 사용 하기로 하고 서버 이관(?)을 실행에 옮겼다.
Fig 1 시스탬 구조도
그리고 나서 artifact uri path를 변경해야 하는 상황이 발생했다.(누가 옮겨 달라고 부탁해서...)
기존 실험과 관련된 checkpoint 등의 artifact도 변경된 artifact uri path 로 옮기고 mlflow ui를 실행하니 artifact가 하나도 표시가 안된다. 그래서 mysql에 등록된 기존 experiment와 runs의 artifact uri path를 변경된 경로로 바꾸려고 mysql client 로 접속해 update 쿼리를 실행했다. lifecycle_stage가 'deleted'인 몇몇 run이 보기길래 이것도 지웠다.
지우고 나니 잠시 뒤 부터 mysql server crash되면서 무한 restart 되기 시작했다. docker-compose ps 로 보니 mysql server status 가 restarting 만 계속 뜬다.
아래 명령어로 로그를 확인 했다.
docker logs mysql_server
Fig 2 와 같은 로그가 뜬다.
Fig 2. mysql server error log
원인을 찾기 위해 Fig 2 error log를 분석하던 도중 'there may be corruption in the InnoDB tablespace.' 라는 문구가 눈에 띄었고 검색을 하며 찾던 중 Fig 3 와 같은 단서를 찾았다.
Fig 3. error about multiple mysql server
Fig 1.에서 PC1에서 돌던 서버를 PC2로 옮기는 과정에서 혹시 PC1의 mysql 서버를 다운 시키지 않았나? 라는 생각이 들어 확인해 보니 아직 돌고 있다. 하나의 물리적인 database 파일에 대해 mysql server 두개가 접근 및 수정을 하고 있었던 것이다. 즉 Fig 4와 같이 mysql 서버가 동작 하고 있었던 것이다.
Fig 4. issue를 발생 시킨 원인으로 추정되는 mysql 서버 운영 형태
locking이 disable된 건지는 내가 dbms 전문가가 아닌지 모르겠으나 가장 의심되는 상황이었다.
해결 방법:
해결방법은 Fig 1 (B)에 있는 PC2에서 실행한 것이다. PC2의 os,툴, 프로그램 등의 버전은 Env info의 PC2 XX 를 참조하기 바란다.
복구를 시도했지만 db 전문가가 아니어서 인지 실패 했다.
실패 한 방법을 간단히만 언급하자면 my.cnf에 innodb_force_recovery=6 을 추가해 복구 모드로 mysql server 실행 후 복구 시도 했지만 레벨 6에서는 table drop 및 import 가 안되어 실패 했다.
내 목적은 어디까지나 mlflow로 실험 및 모델 관리이므로 목적을 가장 쉽게 달성 할수 있는 방법으로
crash 된 database 백업 후 새로운 database를 구축 하고 백업 본을 임포트 해서사용 하기로 했다.
(이 방법은 database가 크면 사용 하기 힘들거 같기도 하다.. 나의 경우엔 다행히 database 가 작았다.)
절차는 아래와 같다.
step 1. mysql server를 recovery mode로 실행하기 위해 /etc/my.cnf 파일 수정. 나의 경우 mysql 공식 docker image를 사용 하고 있었는데 container 내부에서 vi, vim, nano등 text에디터가 설치된 흔적을 찾지 못해 my.cnf 파일을 host os로 복사 후 수정해 사용했다.
docker container side:
cp /etc/my.cnf /backup/space
# /backup/space는 container 실행시 마운트한 host 의 home directory 이다.
host side:
vim /home/my.cnf
[mysqld]
innodb_force_recovery=6
step 2. 수정된 my.cnf를 이용해 mysql server를 실행하기 위해 mysql server container 재 실행
삭제 하는 이유는 mysql docker 이미지로 mysql server를 실행하면 최초 실행에만 /var/lib/mysql 에 database관리를 위한 설정 파일들을 세팅 하기 때문이다. 따라서 기존 사용 하던 docker 이미지 자체를 지우고 새로 pull 해야 한다.
step 4. 아래 그림 Fig 5와 같이 새로운 database 를 구축할 mysql_new 디렉토리를 생성.
mkdir /nas/mysql_new
Fig 5. 새 database dir 생성 및 마운트
step 5. mysql server 실행
이걸 할수 있는 방법은 여러가지가 있지만 나는 docker compose를 이용해 server들을 관리하므로 그냥 내 경우로 정리한다.
step 6. step 5까지 실행 하면 mysql server 가 필요한 설정 파일들을 /nas/mysql_new(container 내부 경로 /var/lib/mysql) 에 생성 했을 것이다. 이제 새로 생성된 database에 step 2에서 백업한 기존 실험 기록들을 restore 해보자.
아래 명령으로 mysql server 가 실행되고 있는 container 에 연결해 mysql client 를 실행 하자.
#host 의 terminal 에서
host$ docker exec -it mlsql_server bash
bash$ mysql -u mysql -p
passwd:
패스워드를 입력하고 myql client cli가 실행 되면 아래 명령을 입력한다.
mysql> use ObjectDetections; #내 database 이름 이다. 복구하고자 하는 database 이름으로 대체 하면 된다.
mysql> set autocommit=0; #큰 데이터 파일을 위해 속도 증가를 위해 오토 커밋을 끄는 과정인데 생략해도 된다.
# restore backup database. step 2에서 백업했던 database 파일이다. 나의 경우 이게 /backup/space/에 위치한다.
mysql> source /backup/space/backup_objectdetection_database.sql;
step 7. 이제 mysql 과 mlflow tracking 서버를 모두 시작(또는 재시작) 하면 된다. 무한 restart 되던 mysql server 가 정상적으로 start 되고 mlflow ui web 화면을 통해 복원한 실험 결과도 확인할 수 있다.
log-parameter failed with exception HTTPConnectionPool(host='localhost', port=5000): Max retries exceeds with url: api/2.0/mlflow/runs/log-parameter (Caused by ResponseError('too many 500 error responses'))
에러가 발생한 시점은 mlflow를 로컬 파일 시스템에서 사용하다
mlflow server와 mysql server를 연동 시켜 사용하려고 시스템을 구축한 직후 이다.
시스템 구축에 사용된 mlflow 와 mysql 버전은 아래와 같다.
mysql server version: 8.0.28
mlflow version: 1.24
Error
Fig 1. Error
기존 환경:
mlflow를 아래 Fig 2와 같이 로컬 환경에서 사용
Fig 2. mlflow on localhost (mlflow 홈페이지에서 참조)
문제 발생 환경
총 3개의 docker container(mysql_server, mlflow_server, model_train_server)를 docker-compose로 실행하여
mysql server를 mlflow server의 backend-store-uri 로 사용 하는 아래 그림 Fig 3. 과 같이 시스템을 구축하는 과정에서 발생
Fig 3. mlflow with remote tracking server, backend and artifact stores
원인 & 해결
위 에러는 mlflow.log_param() 이 실행되는 도중에 발생했다. 딥러닝 모델을 학습할 때 사용 된 하이퍼 파라미터와 모델 configuration 을 기록 하기 위해 log_param을 사용 하고 있었다.
문제는 모델 configuration 을 표현 하는 dictionary 로 key가 꽤 많고 value도 꽤 많은,
즉 사이즈가 큰 dict를 serialize해tj log_param으로 기록 하려고 시도하는 과정에서 발생한 것으로 보인다.
나의 경우 해결 방법이 간단했는데 log_param으로 기록 하던 값들 중 dictionary로 그룹화 되어 사이즈가 큰편에 속하는 것 값들은 mlflow.log_dict 으로 artifact로 저장하고 string이나 int, float등의 단일 값들을 log_param으로 기록 하는 것으로 해결했다.
다만, 기존 환경인 mlflow on localhost에서는 문제가 발생하지 않은 것으로 보아 log_param() 메서드가 serialize 한 값을 urllib를 이용해 보낼수 있는 크기에 상하선이 있는것 같은데 이상한선이 어떤 값인지는 확인해 보지 않았다.
2021년 부터 딥러닝 모델 학습 중 관찰 하고 싶은 metric 을 로깅 하기 위해 mlflow를 사용 하기 시작했다. 그 이전엔 tensorboard를 사용했지만 서로 다른 문제를 풀기 위한 모델들의 학습 결과를 깔끔하게 분리해 관리하기에 불편함을 느껴 대안을 찾던 중 ui가 나름 마음에 들고 학습 메트릭 로깅부터 모델 저장 관리 까지 전체적인 life cycle관리가 가능하다는 이유에서 mlflow 를 선택했다. 물론 지금 당장은 무료 라는 사실 또한 굉장히 중요한 선택 요인이었다.
mlflow에서는 experiment, run이라는 개념이 존재해서 서로 다른 문제를 풀기 위한 모델들의 학습 결과를 깔끔하게 분리해 관리 할 수 있다. 하나의 experiment는 여러개의 run을 가질수 있다.
나의 경우 이 두 가지를 다음과 같은 목적에 따라 사용한다.
1. experiment: 어떤 문제를 풀고자 하는가에 해당. 예를 들어 object detection 문제와 segmentation 문제가 있다고 할 때 이 둘을 서로 다른 experiment로 나누어 관리 한다. 왜냐 하면 두 문제를 풀기 위해 수만은 모델들을 테스트 할텐데 segmentation 모델과 objectdetection 모델을 서로 같은 metric으로 비교할 일은 없으니 같은 문제를 풀기위해 실험한 것들끼리만 experiment로 묶어서 관리한다.
mlflow.get_experiment_by_name(exp_name): exp_name 이라는 이름의 experiment가 있는 지 검색해서 있으면 리턴
2. run: 하나의 experiment, 즉 하나의 목적을 달성하기 이 위해 하이퍼 파라미터를 바꾸어 테스트 하거나 모델을 바꾸어 테스트 할 경우 서로 모델의 성능 비교. 또는 하이퍼 파라미터 변경에 따른 동일 모델의 성능을 비교할 경우 각각의 경우에 구분가능한 이름을 붙여 관리할 목적으로 사용.
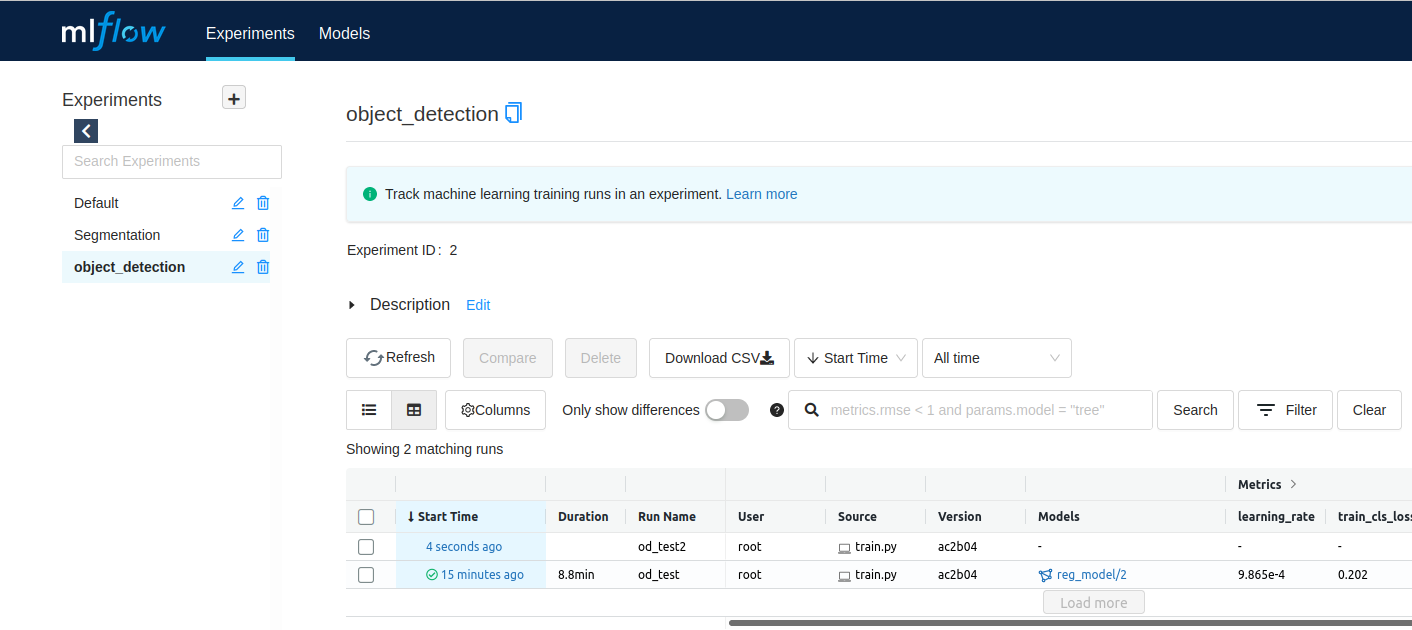
아래에서 설명 할 mlflow ui 를 이용해 웹에서 Fig 1. 과 같은 화면이 나타난다.
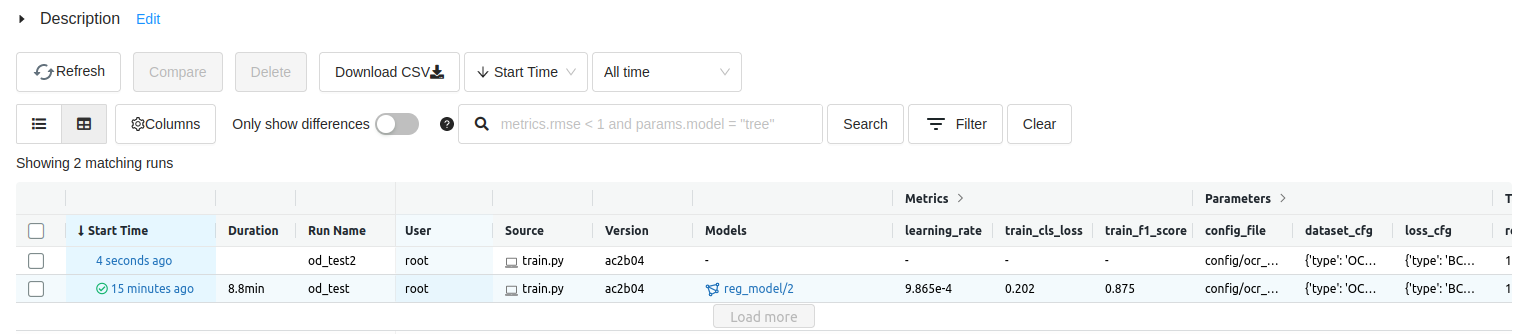
Fig 1의 좌측 상단 mlflow 라는 글자 아래 Experiment 라는 글이 있고 그 아래 default, segmentation, object detection 이라는 3개가 있는데 각각은 서로 다른 목적 가지는 테스크를 구분하기 위해 사용했다.
Fig 1.의 중앙 부분은 object detection 테스크 하위에서 실행 된 run을 보여주는데 Run Name 이라는 섹션에 보면 od_test, od_test2 라는 이름의 run들이 실행 된 것을 볼수 있다. 행 별로 각 run 에서 로깅된 metric, parameter 등을 확인 할 수 있다.
Fig 1. Experiment와 run의 개념 이해를 돕기 위한 예제
주로사용 하는 mlflow 기능
mlflow에서 내가 가장 자주 사용 하는 기능은 학습 중 관잘하고 싶은 메트릭을 로깅 하고 시각화 하는 mlflow tracking 과 mlflow ui이다. (최근엔 model registry 기능을 사용해 배포 모델 버전 관리도 하기 시작했다.)
mlflow tracking 은 모델 학습시 사용된 파라미터 로깅, 코드 버전, metrics, 모델, 체크 포인트 등을 로깅할 수 있는 API 와 로깅된 값을들 웹으로 편리하게 볼수 있는 UI 기능을 제공한다.
파라미터와 메트릭, 모델등을 로깅 하기 위해서는 간단히 아래 처럼 api 를 사용 할수 있다. (아래 코드는 이렇게 사용 할 수 있다고 예를 든 것이므로 실제 적용 할때는 기존에 있는 experiment의 하위에 run생성할 경우 등등을 고려해 구현해서 사용해야 한다.)
import mlflow
# 로깅하고자 하는 대상들이 저장될 위치를 지정
mlflow.set_tracking_uri("file:///home/mlrun_logs")
experiment_id = mlflow.create_experiment('실험이름') #새로운 실험생성
experiment = mlflow.get_experiment(experiment_id)
self.run = mlflow.start_run(run_name = run_name, experiment_id=experiment.experiment_id)
# 'initial_lr'은 key 이고 init_lr은 해당 키에 대응 하는 실제 값
mlflow.log_param('initial_lr', init_lr)
for i in range(max_epoch):
loss = model(input)
mlflow.log_metric('loss', loss) # 'loss' 는 key 이고 loss는 값
#아래는 모델을 로깅하는 방식으로 첫번째 인자는 model 또는 torch.jit.script 로 변환된 모델
#두번 째 인자는 모델을 저장할 위치
mlflow.pytorch.log_model(model, 'path_to_model_save_location')
로깅한 값들을 보고 싶으면 mlflow ui 명령을 terminal 에서 실행 하면 된다.
예를 들어 로깅 하고자 하는 값들이 /home/mlrun_logs 에 저장되었다면 아래 처럼 mlflow ui 명령을 입력하면 된다.
위 명령에서 -p 9999 는 mlflow ui가 9999 번 포트에서 서빙되게 설정하는 것이고 -h 0.0.0.0은 외부에서 mlflow ui 웹에 접속 가능 하게 하기 위함이다. 이렇게 -h 0.0.0.0 옵션을 넣어 실행하면 mlflow ui 가 원격 서버에서 실행중이어도 '원격서버ip:9999' 를 크롬, 파이어 폭스등의 주소창에 입력해서 mlflow ui 웹에 접속이 가능 하다.
아래는 mlflow ui 화면 이다. Run Name이 od_test 인 행을 보면 mlflow.log_metric으로 로깅한 값들은 Metric 섹션에 나타나고 mlflow.log_param으로 로깅한 값들은 Parameters 섹션에 나타난다. 깔끔해 보기가 편리하다.
Fig 2.
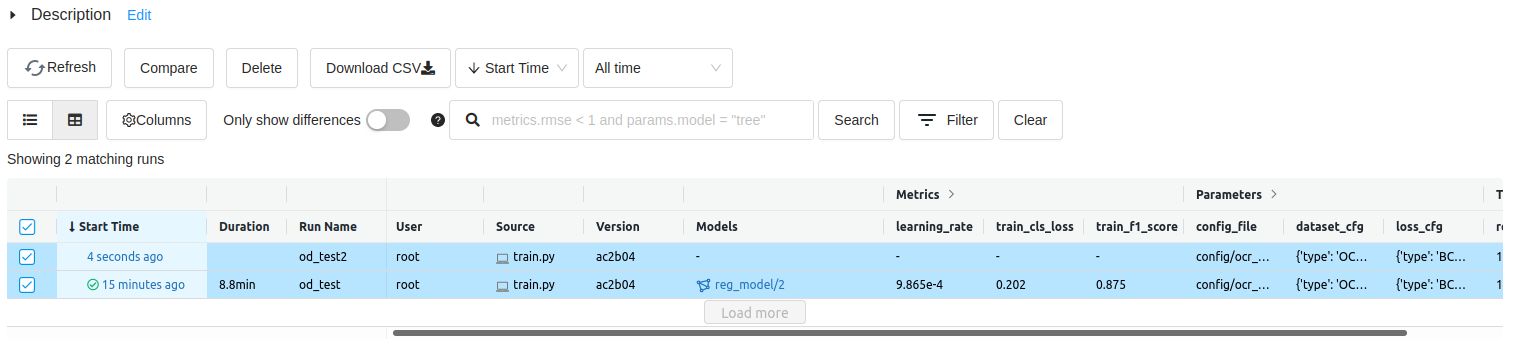
run들 사이의 비교를 하고 싶으면 아래 그림 Fig 3 와 같이 비교하고 싶은 run들을 체크하고 활성화된 compare 버튼을 누르면 효과 적으로 비교 할 수 있다.
Fig 3. compare 기능
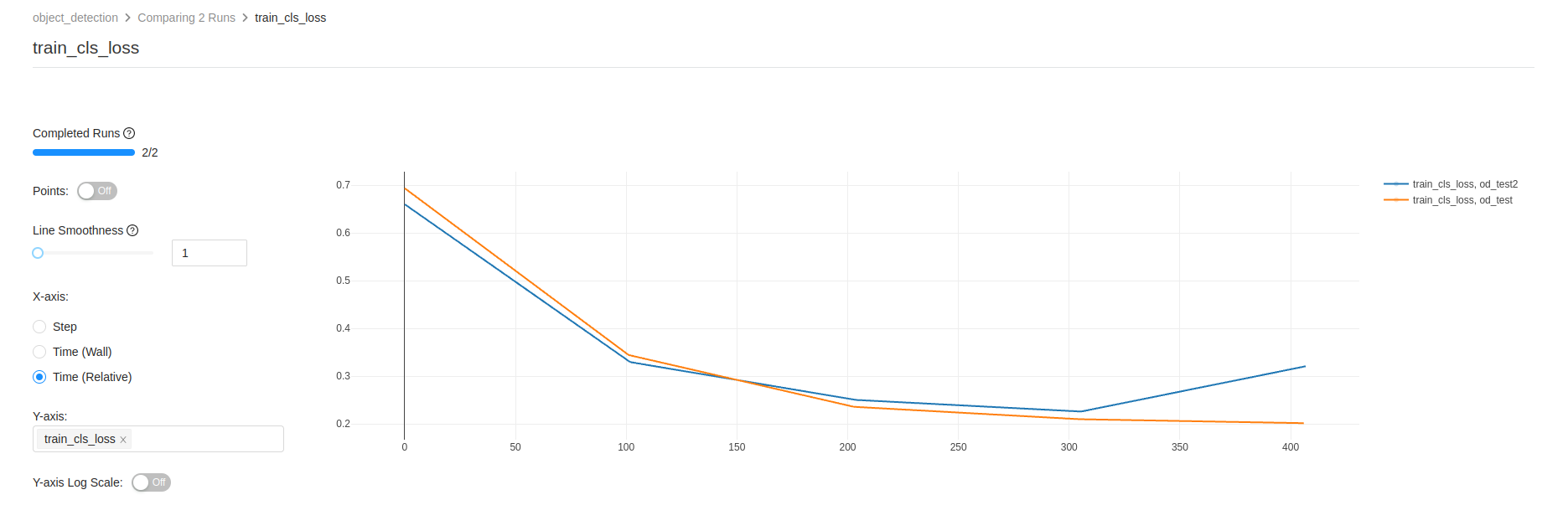
비교 기능을 이용 하면 아래 그림 Fig 4와 같이 서로다른 run들의 metric 변화를 그래프로 비교 할 수도 있다.
Fig 4. comapre 기능을 이용해 서로 다른 run의 metric을 graph로 비교